Population Comparison
This is a notebook going through population comparison of the ExoComp table of chemical equilibrium retrieval results. This shows the calculations contained in the Section 3 of the paper “The Library of Exoplanet Atmospheric Composition Measurements: Population Level Trends in Exoplanet Composition with ExoComp”.
The paper used ExoComp commit f55bde2.
[1]:
from exocomp import Abund
from IPython.display import display
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
# Suppress slice copy warning
pd.options.mode.chained_assignment = None # default='warn'
cs = ['#1f77b4', '#ff7f0e', '#d62728','#2ca02c', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
os.makedirs('./paper_figs/', exist_ok=True)
[2]:
# Read in various datasets used throughout
#data = pd.read_csv('Exoplanet_Atmo_Measurements.csv',comment='#')
#data = pd.read_csv('Exoplanet_Atmo_Measurements_8_13_25.csv',comment='#')
#data = pd.read_csv('Exoplanet_Atmo_Measurements_8_24_25.csv',comment='#')
data = pd.read_csv('Exoplanet_Atmo_Measurements_9_18_25.csv',comment='#')
stars = pd.read_csv('hypatia-26072025.csv')
bds = pd.read_csv('zalesky_22_BDs.txt') #only M/H and C/O verified after transcription!!
uhj_list = ['WASP-18 b','WASP-121 b','WASP-76 b', 'WASP-178 b','MASCARA-1 b','WASP-189 b','WASP-33 b','KELT-20 b']
[3]:
# Convert to O/H, C/H, and Ref/H to standardize solar
data['O/H'] = 0.0
data['C/H'] = 0.0
data['Fe/H'] = 0.0
data['O/H Upper'] = 0.0
data['C/H Upper'] = 0.0
data['Fe/H Upper'] = 0.0
data['O/H Lower'] = 0.0
data['C/H Lower'] = 0.0
data['Fe/H Lower'] = 0.0
droplist = [0, 1, 2] # In case we want to neglect a data point. Here, we drop WASP-39b, WASP-94Ab, WASP-96b b/c in prep.
for i in range(1,len(data)):
if data['Retrieval Type'].iloc[i] in ['ForMoSA']: # Not including grid-search techniques right now
droplist.append(i)
continue
g = Abund(retrieval = data['Retrieval Type'].iloc[i])
if data['Metallicity Type'].iloc[i] == 'O/H':
g.mh_type = 'O/H'
g.co_type = 'C/H'
elif data['Metallicity Type'].iloc[i] == 'C/H':
g.mh_type = 'C/H'
g.co_type = 'O/H'
else:
g.mh_type = '(O+C)/H'
g.co_type = 'MH_Preserve'
# Use exocomp to convert from metallicity and C/O to O/H and C/H
bulk,bulk_err = g.convert_bulk_abundance(data['Metallicity'].iloc[i],data['C/O'].iloc[i],
mh_err = [data['Metallicity Lower'].iloc[i],data['Metallicity Upper'].iloc[i]],
co_err = [data['C/O Lower'].iloc[i],data['C/O Upper'].iloc[i]],)
data['O/H'].iloc[i] = bulk['O']
data['C/H'].iloc[i] = bulk['C']
data['Fe/H'].iloc[i] = bulk['Fe']
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
# Drop entries in the droplist
for i in droplist:
data = data.drop(i)
data.reset_index()
Using Asplund09 solar abundances
Using Lodders10 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Lodders10 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund21 solar abundances
Sometimes POSEIDON varies O/H for C/O (Meech et al. 2025)
Using Asplund09 solar abundances
Sometimes POSEIDON varies O/H for C/O (Meech et al. 2025)
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Sometimes POSEIDON varies O/H for C/O (Meech et al. 2025)
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
Using Lodders10 solar abundances
Using Asplund09 solar abundances
Using Asplund09 solar abundances
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:32: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H'].iloc[i] = bulk['O']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:33: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H'].iloc[i] = bulk['C']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:34: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H'].iloc[i] = bulk['Fe']
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:35: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Upper'].iloc[i] = bulk_err['O'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:36: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Upper'].iloc[i] = bulk_err['C'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:37: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Upper'].iloc[i] = bulk_err['Fe'][1]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:38: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['O/H Lower'].iloc[i] = bulk_err['O'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:39: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['C/H Lower'].iloc[i] = bulk_err['C'][0]
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3076383045.py:40: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['Fe/H Lower'].iloc[i] = bulk_err['Fe'][0]
[3]:
| index | Planet | Reference | Status | Geometry | Obs | C/O | C/O Lower | C/O Upper | Metallicity | ... | Stellar Mass Upper | O/H | C/H | Fe/H | O/H Upper | C/H Upper | Fe/H Upper | O/H Lower | C/H Lower | Fe/H Lower | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | WASP-178 b | Lothringer et al. 2025 | Published | Transit | WFC3/G280+WFC3/G102+WFC3/G141+NIRSpec/G395H | 0.010 | 0.01 | 0.01 | 1.470000 | ... | 0.110 | 10.160000 | 8.160000 | 8.970000 | 0.280000 | 0.280179 | 0.280000 | 1.100000 | 1.100045 | 1.100000 |
| 1 | 4 | HD 189733 b | Fu et al. 2024 | Published | Transit | NIRCAM/F322W2+NIRCam/F444W | 0.200 | 0.20 | 0.00 | 0.602060 | ... | 0.080 | 9.403082 | 8.704112 | 8.102060 | 0.096910 | 0.096910 | 0.096910 | 0.124939 | 0.124939 | 0.124939 |
| 2 | 5 | HD 209458 b | Xue et al. 2024 | Published | Transit | NIRCAM/F322W2+NIRCam/F444W | 0.080 | 0.05 | 0.09 | 0.477121 | ... | 0.090 | 10.004031 | 8.907121 | 7.977121 | 0.378823 | 0.367977 | 0.367977 | 0.183052 | 0.176091 | 0.176091 |
| 3 | 6 | HD 149026 b | Bean et al. 2023 | Published | Eclipse | NIRCAM/F322W2+NIRCam/F444W | 0.840 | 0.03 | 0.03 | 2.090000 | ... | 0.330 | 10.780000 | 10.704279 | 9.590000 | 0.320000 | 0.321403 | 0.320000 | 0.350000 | 0.351283 | 0.350000 |
| 4 | 7 | HD 149026 b | Gagnebin et al. 2024 | Published | Eclipse | NIRCAM/F322W2+NIRCam/F444W | 0.670 | 0.27 | 0.06 | 1.146128 | ... | 0.330 | 9.806128 | 9.632203 | 8.596128 | 0.367977 | 0.372836 | 0.367977 | 0.268845 | 0.381022 | 0.268845 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 61 | 65 | WASP-189 b | Lesjak et al. 2025 | Published | Eclipse | VLT/CRIRES+ | 0.320 | 0.14 | 0.41 | 1.400000 | ... | 0.070 | 10.090000 | 9.595150 | 8.900000 | 1.390000 | 1.449207 | 1.390000 | 0.600000 | 0.616117 | 0.600000 |
| 62 | 66 | WASP-121 b | Pelletier et al. 2025 | Submitted | Eclipse | NIRISS/SOSS | 0.820 | 0.09 | 0.05 | 1.240000 | ... | 0.080 | 9.860132 | 9.773946 | 8.740000 | 0.370000 | 0.370000 | 0.370000 | 0.350000 | 0.350000 | 0.350000 |
| 63 | 67 | V1298 Tau b | Barat et al. 2025 | Published | Transit | NIRSpec/G395H | 0.220 | 0.05 | 0.06 | 0.600000 | ... | 0.060 | 9.360323 | 8.702746 | 8.050000 | 0.400000 | 0.400000 | 0.400000 | 0.600000 | 0.600000 | 0.600000 |
| 64 | 68 | WD 0806 b | Voyer et al. 2025 | Published | Eclipse | MIRI/LRS | 0.340 | 0.06 | 0.06 | -0.130000 | ... | -99.000 | 8.623098 | 8.154577 | 7.370000 | 0.070000 | 0.070000 | 0.070000 | 0.060000 | 0.060000 | 0.060000 |
| 65 | 69 | KELT-7 b | Ahrer et al. 2025 | In Press | Transit | NIRSpec/G395H | 0.585 | 0.16 | 0.16 | 0.930000 | ... | 0.066 | 9.592844 | 9.360000 | 8.430000 | 0.313847 | 0.270000 | 0.270000 | 0.943663 | 0.930000 | 0.930000 |
66 rows × 41 columns
[4]:
# Define some functions for combining multiple entries for the same planet
# Should spin this off into a .py file, but useful to look at in here
def weighted_avg_and_se(df, val_col, err_low_col, err_up_col):
# Use the maximum of the lower and upper errors as the weight
weights = 1 / np.maximum(df[err_low_col], df[err_up_col])**2
avg = np.average(df[val_col], weights=weights)
se = np.sqrt(1 / weights.sum())
return avg, se
def process_group(group):
if len(group) == 1:
return group # no duplicates, keep as is
row = group.iloc[0].copy()
# C/O
row['C/O'], co_se = weighted_avg_and_se(group, 'C/O', 'C/O Lower', 'C/O Upper')
row['C/O Lower'] = co_se
row['C/O Upper'] = co_se
# Metallicity
row['Metallicity'], met_se = weighted_avg_and_se(group, 'Metallicity', 'Metallicity Lower', 'Metallicity Upper')
row['Metallicity Lower'] = met_se
row['Metallicity Upper'] = met_se
#O/H
row['O/H'], oh_se = weighted_avg_and_se(group, 'O/H', 'O/H Lower', 'O/H Upper')
row['O/H Lower'] = oh_se
row['O/H Upper'] = oh_se
#C/H
row['C/H'], ch_se = weighted_avg_and_se(group, 'C/H', 'C/H Lower', 'C/H Upper')
row['C/H Lower'] = ch_se
row['C/H Upper'] = ch_se
#Fe/H
row['Fe/H'], feh_se = weighted_avg_and_se(group, 'Fe/H', 'Fe/H Lower', 'Fe/H Upper')
row['Fe/H Lower'] = feh_se
row['Fe/H Upper'] = feh_se
return pd.DataFrame([row])
grouped = data.groupby(['Planet', 'Geometry'], group_keys=False)
result = grouped.apply(process_group).reset_index(drop=True)
result
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/2177664126.py:46: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
result = grouped.apply(process_group).reset_index(drop=True)
[4]:
| Planet | Reference | Status | Geometry | Obs | C/O | C/O Lower | C/O Upper | Metallicity | Metallicity Lower | ... | Stellar Mass Upper | O/H | C/H | Fe/H | O/H Upper | C/H Upper | Fe/H Upper | O/H Lower | C/H Lower | Fe/H Lower | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2M0122 b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.370000 | 0.080000 | 0.080000 | -0.300000 | 0.220000 | ... | 0.020 | 8.561798 | 8.130000 | 7.200000 | 0.170000 | 0.150000 | 0.150000 | 0.234094 | 0.220000 | 0.220000 |
| 1 | 51 Eri b | Brown-Sevilla et al. 2023 | Published | Direct | VLT/SPHERE | 0.380000 | 0.090000 | 0.090000 | 0.260000 | 0.300000 | ... | 0.050 | 9.110216 | 8.690000 | 7.760000 | 0.313209 | 0.300000 | 0.300000 | 0.313209 | 0.300000 | 0.300000 |
| 2 | AB Pic b | Gandhi et al. 2025 | Published | Direct | VLT/CRIRES+ | 0.590000 | 0.010000 | 0.010000 | 0.540000 | 0.080000 | ... | 0.100 | 9.230000 | 9.000852 | 8.000000 | 0.080000 | 0.080623 | 0.080000 | 0.080000 | 0.080623 | 0.080000 |
| 3 | AF Lep b | Zhang et al. 2023 | Published | Direct | VLT/SPHERE | 0.611475 | 0.076822 | 0.076822 | 1.268293 | 0.156174 | ... | 0.060 | 9.865419 | 9.698293 | 8.768293 | 0.176294 | 0.156174 | 0.156174 | 0.176294 | 0.156174 | 0.156174 |
| 4 | DH Tau b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.540000 | 0.050000 | 0.060000 | -0.300000 | 0.200000 | ... | 0.000 | 8.397606 | 8.130000 | 7.200000 | 0.161555 | 0.150000 | 0.150000 | 0.206155 | 0.200000 | 0.200000 |
| 5 | GJ 3470 b | Beatty et al. 2024 | Published | Transit | NIRCAM/F322W2+NIRCam/F444W | 0.350000 | 0.100000 | 0.100000 | 2.100000 | 0.120000 | ... | 0.050 | 10.849869 | 10.393937 | 9.600000 | 0.120000 | 0.120000 | 0.120000 | 0.120000 | 0.120000 | 0.120000 |
| 6 | GQ Lup b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.540000 | 0.008944 | 0.008944 | 0.458875 | 0.134518 | ... | 0.160 | 9.135558 | 8.888875 | 7.958875 | 0.134871 | 0.134518 | 0.134518 | 0.134871 | 0.134518 | 0.134518 |
| 7 | GSC 6214-210 b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.700000 | 0.060000 | 0.070000 | 0.150000 | 0.300000 | ... | 0.110 | 8.734902 | 8.580000 | 7.650000 | 0.193132 | 0.180000 | 0.180000 | 0.305941 | 0.300000 | 0.300000 |
| 8 | HAT-P-14 b | Liu et al. 2025 | Published | Transit | NIRISS/SOSS+NIRSpec/G395H | 0.410000 | 0.200000 | 0.240000 | -0.080000 | 0.980000 | ... | 0.045 | 8.737216 | 8.350000 | 7.420000 | 0.921792 | 0.890000 | 0.890000 | 1.000200 | 0.980000 | 0.980000 |
| 9 | HD 149026 b | Bean et al. 2023 | Published | Eclipse | NIRCAM/F322W2+NIRCam/F444W | 0.837927 | 0.029817 | 0.029817 | 1.641682 | 0.253605 | ... | 0.330 | 10.317433 | 10.211706 | 9.117933 | 0.253605 | 0.258269 | 0.253605 | 0.253605 | 0.258269 | 0.253605 |
| 10 | HD 189733 b | Zhang et al. 2025 | Published | Eclipse | NIRCAM/F322W2+NIRCam/F444W | 0.430000 | 0.050000 | 0.060000 | 0.680000 | 0.110000 | ... | 0.080 | 9.404867 | 9.038335 | 8.180000 | 0.150000 | 0.150000 | 0.150000 | 0.110000 | 0.110000 | 0.110000 |
| 11 | HD 189733 b | Fu et al. 2024 | Published | Transit | NIRCAM/F322W2+NIRCam/F444W | 0.347627 | 0.108998 | 0.108998 | 0.567460 | 0.090081 | ... | 0.080 | 9.334853 | 8.785573 | 8.067460 | 0.090081 | 0.090081 | 0.090081 | 0.090081 | 0.090081 | 0.090081 |
| 12 | HD 209458 b | Xue et al. 2024 | Published | Transit | NIRCAM/F322W2+NIRCam/F444W | 0.163834 | 0.053517 | 0.053517 | 0.192218 | 0.161513 | ... | 0.090 | 9.187464 | 8.636464 | 7.692218 | 0.162868 | 0.173203 | 0.161513 | 0.162868 | 0.173203 | 0.161513 |
| 13 | HD 80606 b | Sikora et al. 2025 | Submitted | Eclipse | NIRSpec/G395H | 0.690000 | 0.140000 | 0.140000 | -0.110000 | 0.550000 | ... | 0.270 | 8.580000 | 8.418849 | 7.390000 | 0.480000 | 0.500000 | 0.480000 | 0.550000 | 0.567539 | 0.550000 |
| 14 | HIP 65 b | Bazinet et al. 2024 | Published | Eclipse | Gemini/IGRINS | 0.720000 | 0.300000 | 0.130000 | -0.760000 | 0.480000 | ... | 0.027 | 7.884675 | 7.742007 | 6.740000 | 0.420000 | 0.420000 | 0.420000 | 0.480000 | 0.480000 | 0.480000 |
| 15 | HR 8799 b | Nasedkin et al. 2024 | Published | Direct | VLT/GRAVITY | 0.780000 | 0.040000 | 0.030000 | 0.960000 | 0.080000 | ... | 0.300 | 9.497905 | 9.390000 | 8.460000 | 0.085440 | 0.080000 | 0.080000 | 0.089443 | 0.080000 | 0.080000 |
| 16 | HR 8799 c | Nasedkin et al. 2025 | Published | Direct | VLT/GRAVITY | 0.660000 | 0.010000 | 0.010000 | 1.270000 | 0.060000 | ... | 0.300 | 9.880456 | 9.700000 | 8.770000 | 0.050990 | 0.050000 | 0.050000 | 0.060828 | 0.060000 | 0.060000 |
| 17 | HR 8799 d | Nasedkin et al. 2026 | Published | Direct | VLT/GRAVITY | 0.600000 | 0.060000 | 0.040000 | 1.200000 | 0.200000 | ... | 0.300 | 9.851849 | 9.630000 | 8.700000 | 0.203961 | 0.200000 | 0.200000 | 0.208806 | 0.200000 | 0.200000 |
| 18 | HR 8799 e | Molliere et al. 2020 | Published | Direct | VLT/GRAVITY | 0.863529 | 0.019403 | 0.019403 | 1.442305 | 0.164643 | ... | 0.040 | 9.998594 | 9.872305 | 8.942305 | 0.167126 | 0.164643 | 0.164643 | 0.167126 | 0.164643 | 0.164643 |
| 19 | KELT-20 b | Finnerty et al. 2025 | Published | Transit | Keck/KPIC | 0.100000 | 0.100000 | 0.400000 | 1.000000 | 0.700000 | ... | 0.140 | 9.838810 | 8.838810 | 8.500000 | 0.700000 | 0.700000 | 0.700000 | 0.700000 | 0.700000 | 0.700000 |
| 20 | KELT-7 b | Ahrer et al. 2025 | In Press | Transit | NIRSpec/G395H | 0.585000 | 0.160000 | 0.160000 | 0.930000 | 0.930000 | ... | 0.066 | 9.592844 | 9.360000 | 8.430000 | 0.313847 | 0.270000 | 0.270000 | 0.943663 | 0.930000 | 0.930000 |
| 21 | MASCARA-1 b | Ramkumar et al. 2025 | Published | Eclipse | VLT/CRIRES+ | 0.740000 | 0.140000 | 0.110000 | -0.330000 | 0.000000 | ... | 0.060 | 8.360000 | 8.229232 | 7.170000 | 1.000000 | 1.006032 | 1.000000 | 0.000000 | 0.140000 | 0.000000 |
| 22 | PDS 70 b | Hsu et al. 2024 | Published | Direct | Keck/KPIC | 0.280000 | 0.120000 | 0.200000 | -0.200000 | 0.500000 | ... | 0.020 | 8.782842 | 8.230000 | 7.300000 | 0.824621 | 0.800000 | 0.800000 | 0.514198 | 0.500000 | 0.500000 |
| 23 | ROXs 12 b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.540000 | 0.050000 | 0.050000 | -0.300000 | 0.200000 | ... | 0.080 | 8.397606 | 8.130000 | 7.200000 | 0.158114 | 0.150000 | 0.150000 | 0.206155 | 0.200000 | 0.200000 |
| 24 | ROXs 42B b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.480000 | 0.080000 | 0.080000 | 0.000000 | 0.520000 | ... | -99.000 | 8.748759 | 8.430000 | 7.500000 | 0.243516 | 0.230000 | 0.230000 | 0.526118 | 0.520000 | 0.520000 |
| 25 | TOI-5205 b | Cañas et al. 2025 | Submitted | Transit | NIRSpec/PRISM | 1.300000 | 0.400000 | 0.400000 | -0.760000 | 0.100000 | ... | 0.020 | 7.930000 | 8.043943 | 6.740000 | 0.170000 | 0.434626 | 0.170000 | 0.100000 | 0.412311 | 0.100000 |
| 26 | Tau Boo b | Panwar et al. 2024 | Published | Eclipse | VLT/CRIRES | 0.832590 | 0.199210 | 0.199210 | -0.509271 | 1.018595 | ... | 0.244 | 8.110199 | 8.023914 | 6.990729 | 1.018595 | 1.018595 | 1.018595 | 1.018595 | 1.018595 | 1.018595 |
| 27 | TrES-4 b | Meech et al. 2025 | Published | Transit | NIRSpec/G395H | 0.350000 | 0.100000 | 0.120000 | -0.150000 | 0.260000 | ... | 0.380 | 8.735932 | 8.280000 | 7.350000 | 0.295466 | 0.270000 | 0.270000 | 0.278568 | 0.260000 | 0.260000 |
| 28 | V1298 Tau b | Barat et al. 2025 | Published | Transit | NIRSpec/G395H | 0.220000 | 0.050000 | 0.060000 | 0.600000 | 0.600000 | ... | 0.060 | 9.360323 | 8.702746 | 8.050000 | 0.400000 | 0.400000 | 0.400000 | 0.600000 | 0.600000 | 0.600000 |
| 29 | WASP-107 b | Sing et al. 2024 | Published | Transit | NIRSpec/G395H | 0.338471 | 0.058571 | 0.058571 | 1.453485 | 0.108070 | ... | 0.020 | 10.176988 | 9.808156 | 8.953485 | 0.108070 | 0.108070 | 0.108070 | 0.108070 | 0.108070 | 0.108070 |
| 30 | WASP-121 b | Smith et al. 2024b | Published | Eclipse | Gemini/IGRINS | 0.890084 | 0.024904 | 0.024904 | 0.790328 | 0.123681 | ... | 0.070 | 9.452744 | 9.392402 | 8.290328 | 0.123681 | 0.124956 | 0.123681 | 0.123681 | 0.124956 | 0.123681 |
| 31 | WASP-121 b | Gapp et al. 2025 | Published | Transit | NIRSpec/G395H | 0.978000 | 0.006000 | 0.004000 | 1.160000 | 0.080000 | ... | 0.070 | 9.850000 | 9.840339 | 8.660000 | 0.060000 | 0.060133 | 0.060000 | 0.080000 | 0.080225 | 0.080000 |
| 32 | WASP-127 b | Kanumalla et al. 2024 | Published | Eclipse | Gemini/IGRINS | 0.680000 | 0.680000 | 0.000000 | 1.590000 | 0.300000 | ... | 0.020 | 10.280000 | 10.112509 | 9.090000 | 0.300000 | 0.300000 | 0.300000 | 0.300000 | 0.743236 | 0.300000 |
| 33 | WASP-15 b | Kirk et al. 2025 | Published | Transit | NIRSpec/G395H | 0.530000 | 0.150000 | 0.090000 | 1.340000 | 0.260000 | ... | 0.160 | 10.045724 | 9.770000 | 8.840000 | 0.294109 | 0.280000 | 0.280000 | 0.300167 | 0.260000 | 0.260000 |
| 34 | WASP-166 b | Mayo et al. 2025 | Submitted | Transit | NIRISS/SOSS+NIRSpec/PRISM | 0.282000 | 0.053000 | 0.078000 | 1.570000 | 0.180000 | ... | 0.060 | 10.342315 | 9.792564 | 9.070000 | 0.170000 | 0.170000 | 0.170000 | 0.180000 | 0.180000 | 0.180000 |
| 35 | WASP-178 b | Lothringer et al. 2025 | Published | Transit | WFC3/G280+WFC3/G102+WFC3/G141+NIRSpec/G395H | 0.010000 | 0.010000 | 0.010000 | 1.470000 | 1.100000 | ... | 0.110 | 10.160000 | 8.160000 | 8.970000 | 0.280000 | 0.280179 | 0.280000 | 1.100000 | 1.100045 | 1.100000 |
| 36 | WASP-18 b | Coulombe et al. 2023 | Published | Eclipse | NIRISS/SOSS | 0.403196 | 0.295808 | 0.295808 | 0.237460 | 0.228827 | ... | 0.060 | 8.927460 | 8.634820 | 7.737460 | 0.228827 | 0.373264 | 0.228827 | 0.228827 | 0.373264 | 0.228827 |
| 37 | WASP-189 b | Lesjak et al. 2025 | Published | Eclipse | VLT/CRIRES+ | 0.320000 | 0.140000 | 0.410000 | 1.400000 | 0.600000 | ... | 0.070 | 10.090000 | 9.595150 | 8.900000 | 1.390000 | 1.449207 | 1.390000 | 0.600000 | 0.616117 | 0.600000 |
| 38 | WASP-19 b | Saha et al. 2025 | Submitted | Eclipse | NIRSpec/PRISM | 0.940000 | 0.030000 | 0.030000 | 1.700000 | 0.700000 | ... | 0.090 | 10.292401 | 10.265529 | 9.200000 | 1.200000 | 1.200000 | 1.200000 | 0.700000 | 0.700000 | 0.700000 |
| 39 | WASP-33 b | Finnerty et al. 2023 | Published | Eclipse | KEck/KPIC | 0.800000 | 0.200000 | 0.100000 | 0.740000 | 0.440000 | ... | 0.350 | 9.364931 | 9.268021 | 8.240000 | 0.440000 | 0.440000 | 0.440000 | 0.440000 | 0.440000 | 0.440000 |
| 40 | WASP-43 b | Yang et al. 2024 | Published | Eclipse | MIRI/LRS | 0.783368 | 0.082073 | 0.082073 | 0.200000 | 0.069544 | ... | 0.050 | 8.740843 | 8.631274 | 7.700000 | 0.112077 | 0.069544 | 0.069544 | 0.112077 | 0.069544 | 0.069544 |
| 41 | WASP-69 b | Schlawin et al. 2024 | Published | Eclipse | NIRCAM/F322W2+NIRCam/F444W+MIRI/LRS | 0.750000 | 0.100000 | 0.190000 | 0.960000 | 0.170000 | ... | 0.140 | 9.597165 | 9.472226 | 8.460000 | 0.200000 | 0.200000 | 0.200000 | 0.170000 | 0.170000 | 0.170000 |
| 42 | WASP-76 b | Mansfield et al. 2024 | Published | Eclipse | Gemini/IGRINS | 0.590000 | 0.140000 | 0.130000 | -0.740000 | 0.170000 | ... | 0.020 | 7.938806 | 7.709658 | 6.760000 | 0.230000 | 0.230000 | 0.230000 | 0.170000 | 0.170000 | 0.170000 |
| 43 | WASP-77 A b | Line et al. 2021 | Published | Eclipse | Gemini/IGRINS | 0.548632 | 0.038062 | 0.038062 | -0.633694 | 0.068547 | ... | 0.070 | 8.044006 | 7.802054 | 6.866306 | 0.073254 | 0.071121 | 0.068547 | 0.073254 | 0.071121 | 0.068547 |
| 44 | WASP-80 b | Wiser et al. 2025 | In Press | Eclipse | NIRCAM/F322W2+NIRCam/F444W+MIRI/LRS | 0.480000 | 0.070000 | 0.060000 | 0.550000 | 0.100000 | ... | 0.050 | 9.259941 | 8.941183 | 8.050000 | 0.120000 | 0.120000 | 0.120000 | 0.100000 | 0.100000 | 0.100000 |
| 45 | WASP-94A b | Ahrer et al. 2025 | Published | Transit | NIRSpec/G395H | 0.490000 | 0.130000 | 0.080000 | 0.340000 | 0.160000 | ... | 0.190 | 9.047017 | 8.737213 | 7.840000 | 0.120000 | 0.120000 | 0.120000 | 0.160000 | 0.160000 | 0.160000 |
| 46 | WD 0806 b | Voyer et al. 2025 | Published | Eclipse | MIRI/LRS | 0.340000 | 0.060000 | 0.060000 | -0.130000 | 0.060000 | ... | -99.000 | 8.623098 | 8.154577 | 7.370000 | 0.070000 | 0.070000 | 0.070000 | 0.060000 | 0.060000 | 0.060000 |
| 47 | beta Pic b | Nowak et al. 2020 | Published | Direct | VLT/GRAVITY | 0.440000 | 0.070000 | 0.050000 | 0.660000 | 0.110000 | ... | 0.027 | 9.446547 | 9.090000 | 8.160000 | 0.139284 | 0.130000 | 0.130000 | 0.130384 | 0.110000 | 0.110000 |
| 48 | kap And b | Xuan et al. 2024 | Published | Direct | Keck/KPIC | 0.580000 | 0.040000 | 0.050000 | -0.100000 | 0.200000 | ... | 0.200 | 8.566572 | 8.330000 | 7.400000 | 0.148661 | 0.140000 | 0.140000 | 0.203961 | 0.200000 | 0.200000 |
49 rows × 40 columns
[5]:
# Define some subgroups by geometry
direct = result[result['Geometry'] == 'Direct']
emission = result[result['Geometry'] == 'Eclipse']
transit = result[result['Geometry'] == 'Transit']
# Split off UHJs so we can mark them as special
# Because they are :).
# Also dissociation...
uhjs = result[result['Planet'].isin(uhj_list)]
[6]:
print(f'Number of final entries: {len((data['Planet']))}')
print(f'Number of unique planets measured: {len(np.unique(data['Planet']))}')
# number after account for multiple entires per planet
# can be more than unique planets, because we can measure planets with different geometries and they'll count towards this
print(f'Number of planet measurements accounting for multiples: {len((result['Planet']))}')
print(f'Number of direct spectroscopy entries: {len((direct['Planet']))}')
print(f'Number of transit spectroscopy entries: {len((transit['Planet']))}')
print(f'Number of emission spectroscopy entries: {len((emission['Planet']))}')
print(f'Number of UHJ entries: {len((uhjs['Planet']))}')
Number of final entries: 66
Number of unique planets measured: 47
Number of planet measurements accounting for multiples: 49
Number of direct spectroscopy entries: 16
Number of transit spectroscopy entries: 15
Number of emission spectroscopy entries: 18
Number of UHJ entries: 8
[7]:
# Make a generic plotting script for pop comparisons
# so that we can make aesthetic changes easier to all plots
def pop_plot(fig,ax,axis1,axis2,plot_direct = True,
axis1_label = None, axis2_label = None):
if axis1_label is None:
axis1_label = axis1
if axis2_label is None:
axis2_label = axis2
if plot_direct is True:
ds = [direct, emission, transit]
labels = ['Direct', 'Eclipse', 'Transmission','UHJ']
markers = ['o', 's', 'd', '*']
colors = ['#2E86AB', '#A23B72', '#F18F01', 'grey']
else:
ds = [emission, transit]
labels = ['Eclipse', 'Transmission','UHJ']
markers = ['s', 'd', '*']
colors = ['#A23B72', '#F18F01', 'grey']
for d, label, marker, color in zip(ds,labels,markers,colors):
ax.errorbar(d[f'{axis1}'], d[f'{axis2}'],
xerr=[d[f'{axis1} Lower'], d[f'{axis1} Upper']],
yerr=[d[f'{axis2} Lower'], d[f'{axis2} Upper']],
fmt=marker, label=label, color=color,
markersize=7, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
ax.errorbar(row[f'{axis1}'], row[f'{axis2}'],
xerr=[[row[f'{axis1} Lower']], [row[f'{axis1} Upper']]],
yerr=[[row[f'{axis2} Lower']], [row[f'{axis2} Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
ax.set_xlabel(f'{axis1_label}', fontsize=15)
ax.set_ylabel(f'{axis2_label}', fontsize=15)
ax.legend(frameon=True, fancybox=True, shadow=False,fontsize=12)
ax.grid(True, alpha=0.3)
ax.minorticks_on()
ax.tick_params(labelsize=12)
ax.yaxis.set_ticks_position('both')
ax.xaxis.set_ticks_position('both')
plt.tight_layout()
Metallicity & CO Plots
[8]:
fig, ax = plt.subplots(figsize=(9, 6))
pop_plot(fig,ax,'Metallicity','C/O')
plt.savefig('./paper_figs/metallicity_co.pdf')
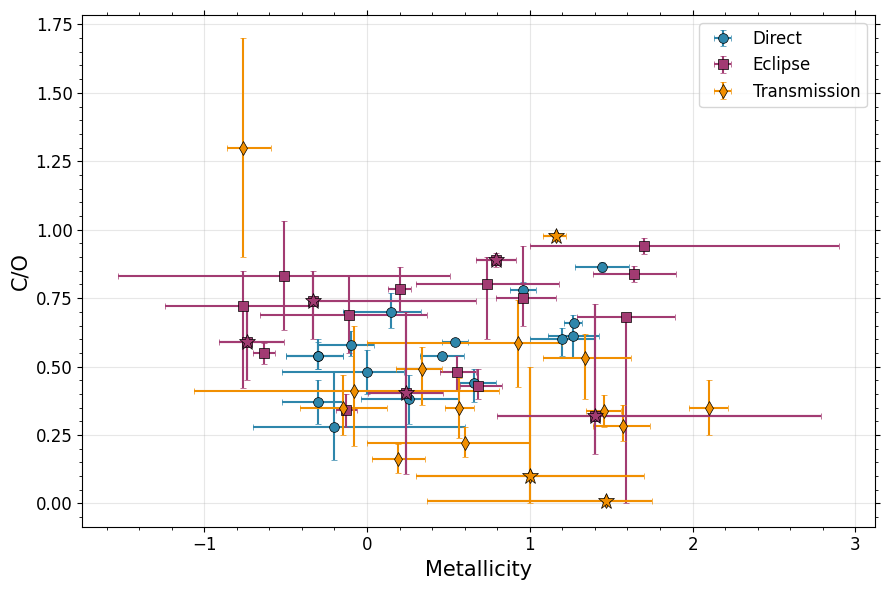
[9]:
data_nircam = data[data['Obs'] == 'NIRCAM/F322W2+NIRCam/F444W']
data_nirspec_g395 = data[data['Obs'] == "NIRSpec/G395H"]
data_soss = data[data['Obs'] == 'NIRISS/SOSS'].drop_duplicates().reset_index(drop=True)
data_nir = pd.concat([data_nircam,data_nirspec_g395]).drop_duplicates().reset_index(drop=True)
#hires
data_gemini = data[data['Obs'].str.contains("Gemini")]
data_espresso = data[data['Obs'].str.contains("ESPRESSO")]
data_crires = data[data['Obs'].str.contains("CRIRES")]
data_hires = pd.concat([data_gemini,data_espresso,data_crires]).drop_duplicates().reset_index(drop=True)
[10]:
data_soss
[10]:
| Planet | Reference | Status | Geometry | Obs | C/O | C/O Lower | C/O Upper | Metallicity | Metallicity Lower | ... | Stellar Mass Upper | O/H | C/H | Fe/H | O/H Upper | C/H Upper | Fe/H Upper | O/H Lower | C/H Lower | Fe/H Lower | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WASP-18 b | Coulombe et al. 2023 | Published | Eclipse | NIRISS/SOSS | 0.60 | 0.60 | 0.00 | 0.012837 | 0.317577 | ... | 0.06 | 8.702837 | 8.480988 | 7.512837 | 0.296834 | 0.296834 | 0.296834 | 0.317577 | 0.678863 | 0.317577 |
| 1 | WASP-121 b | Pelletier et al. 2025 | Submitted | Eclipse | NIRISS/SOSS | 0.82 | 0.09 | 0.05 | 1.240000 | 0.350000 | ... | 0.08 | 9.860132 | 9.773946 | 8.740000 | 0.370000 | 0.370000 | 0.370000 | 0.350000 | 0.350000 | 0.350000 |
2 rows × 40 columns
[34]:
# Plot and print out some properties
do_stats = False
def analyze_and_plot_population(data, population_name, ax, print_stats=True, color='k', print_latex=True):
"""
Analyze a population dataset and add error bar plots to existing axes.
Parameters:
-----------
data : dict or DataFrame
Dictionary/DataFrame containing the population data with keys:
'C/O', 'C/O Lower', 'C/O Upper', 'Metallicity', 'Metallicity Lower',
'Metallicity Upper', 'Mass', 'T_eq', 'O/H', 'C/H'
population_name : str
Name of the population for labeling (e.g., 'Eclipse', 'Transit', 'UHJs')
ax : array of matplotlib axes
Array with at least 2 axes: ax[0] for O/H plot, ax[1] for C/O plot
print_stats : bool, optional
Whether to print statistics (default True)
Returns:
--------
dict : Dictionary containing all calculated statistics
"""
# Calculate weighted averages
co_weights = 1/np.max([data['C/O Lower'], data['C/O Upper']], axis=0)**2
mh_weights = 1/np.max([data['Metallicity Lower'], data['Metallicity Upper']], axis=0)**2
avg_co = np.average(data['C/O'], weights=co_weights)
avg_mh = np.average(data['Metallicity'], weights=mh_weights)
avg_mass = np.average(data['Mass'])
avg_temp = np.average(data['T_eq'])
avg_oh = np.average(data['O/H'])
avg_ch = np.average(data['C/H'])
# Weighted standard deviations
std_co = np.sqrt(np.average((data['C/O'] - avg_co)**2, weights=co_weights))
std_mh = np.sqrt(np.average((data['Metallicity'] - avg_mh)**2, weights=mh_weights))
# Unweighted standard deviations
std_mass = np.std(data['Mass'])
std_temp = np.std(data['T_eq'])
std_oh = np.std(data['O/H'])
std_ch = np.std(data['C/H'])
# Calculate medians
med_oh = np.median(data['O/H'])
med_ch = np.median(data['C/H'])
med_co = np.median(data['C/O'])
med_mh = np.median(data['Metallicity'])
med_mass = np.median(data['Mass'])
med_temp = np.median(data['T_eq'])
# Count number of planets
n_planets = len(data)
# Print statistics if requested
if print_stats:
print(f'{population_name} Spectroscopy ({n_planets} planets):')
print(f' Average C/O = {avg_co:.3f} ± {std_co:.3f}, Average M/H = {avg_mh:.3f} ± {std_mh:.3f}')
print(f' Average Mass = {avg_mass:.2f} ± {std_mass:.2f}, Average T_eq = {avg_temp:.1f} ± {std_temp:.1f}')
print(f' Average O/H = {avg_oh:.3f} ± {std_oh:.3f}, Average C/H = {avg_ch:.3f} ± {std_ch:.3f}')
print(f' Median C/O = {med_co:.3f}, Median M/H = {med_mh:.3f}')
print(f' Median Mass = {med_mass:.2f}, Median T_eq = {med_temp:.1f}')
print(f' Median O/H = {med_oh:.3f}, Median C/H = {med_ch:.3f}')
if print_latex:
latex_output = f"""\\multicolumn{{7}}{{c}}{{\\textbf{{{population_name} Spectroscopy ({n_planets} planets)}}}} \\\\
Average & ${avg_co:.3f} \\pm {std_co:.3f}$ & ${avg_mh:.3f} \\pm {std_mh:.3f}$ & ${avg_oh:.3f} \\pm {std_oh:.3f}$ & ${avg_ch:.3f} \\pm {std_ch:.3f}$ & ${avg_mass:.2f} \\pm {std_mass:.2f}$ & ${avg_temp:.1f} \\pm {std_temp:.1f}$ \\\\
Median & {med_co:.3f} & {med_mh:.3f} & {med_oh:.3f} & {med_ch:.3f} & {med_mass:.2f} & {med_temp:.1f} \\\\"""
print(latex_output)
# Add error bar plots
oh_err = np.std(data['O/H']) / np.sqrt(len(data['O/H']))
co_err = np.std(data['C/O']) / np.sqrt(len(data['C/O']))
ax[0].errorbar(population_name, med_oh, yerr=oh_err, fmt='o',capsize=6,color=color,markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[1].errorbar(population_name, med_co, yerr=co_err, fmt='o',capsize=6,color=color,markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[0].errorbar(population_name, med_oh, yerr=oh_err*np.sqrt(len(data['O/H'])), fmt='o',capsize=6,color=color,markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[1].errorbar(population_name, med_co, yerr=co_err*np.sqrt(len(data['C/O'])), fmt='o',capsize=6,color=color,markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
# Return all statistics as a dictionary
stats = {
'avg_co': avg_co, 'avg_mh': avg_mh, 'avg_mass': avg_mass, 'avg_temp': avg_temp,
'avg_oh': avg_oh, 'avg_ch': avg_ch, 'med_oh': med_oh, 'med_ch': med_ch,
'med_co': med_co, 'med_mh': med_mh, 'med_mass': med_mass, 'med_temp': med_temp
}
return stats
fig,ax = plt.subplots(1,2,figsize=(13,6))
direct_stats = analyze_and_plot_population(direct, 'Direct', ax, print_stats=do_stats,color=cs[0])
# Remove HR 8799 planets to see how much that's changing things... not much actually
data_nohr8799 = data[~data['Planet'].isin(['HR 8799 b','HR 8799 c','HR 8799 d','HR 8799 e'])]
direct_nohr8799 = data_nohr8799[(data_nohr8799['Geometry'] == 'Direct')]
#direct_nohr8799_stats = analyze_and_plot_population(direct_nohr8799, 'Direct \n No HR 8799', ax, print_stats=do_stats,color=cs[1])
#Eclipse
emission_stats = analyze_and_plot_population(emission, 'Eclipse', ax, print_stats=do_stats,color=cs[2])
# Plot non-ultra hots by removing UHJ list
data_nouhj = result[~result['Planet'].isin(uhj_list)]
data_nouhj.reset_index()
emission_nouhj = data_nouhj[(data_nouhj['Geometry'] == 'Eclipse')]
emission_nouhj_stats = analyze_and_plot_population(emission_nouhj, 'Eclipse \n No UHJ', ax, print_stats=do_stats,color=cs[3])
transit_stats = analyze_and_plot_population(transit, 'Transit', ax, print_stats=do_stats,color=cs[4])
transit_nouhj = data_nouhj[(data_nouhj['Geometry'] == 'Transit')]
transit_nouhj_stats = analyze_and_plot_population(transit_nouhj, 'Transit \n No UHJ', ax, print_stats=do_stats,color=cs[5])
uhjs_stats = analyze_and_plot_population(uhjs, 'UHJs', ax, print_stats=do_stats,color=cs[6])
# Obs coverage - use 'data', not 'result' here because we want to see how individual obs compare.
data_nircam = data[data['Obs'] == 'NIRCAM/F322W2+NIRCam/F444W']
data_nirspec_g395 = data[data['Obs'].str.startswith("NIRSpec/G395")]
data_soss = data[data['Obs'] == 'NIRISS/SOSS'].drop_duplicates().reset_index(drop=True)
data_nir = pd.concat([data_nircam,data_nirspec_g395]).drop_duplicates().reset_index(drop=True)
#hires
data_gemini = data[data['Obs'].str.contains("Gemini")]
data_espresso = data[data['Obs'].str.contains("ESPRESSO")]
data_crires = data[data['Obs'].str.contains("CRIRES")]
data_hires = pd.concat([data_gemini,data_espresso,data_crires]).drop_duplicates().reset_index(drop=True)
nir_soss =analyze_and_plot_population(data_soss, '1-3um', ax, print_stats=do_stats, color='grey')
nir_stats =analyze_and_plot_population(data_nir, '3-5um', ax, print_stats=do_stats, color='k')
hires_stats = analyze_and_plot_population(data_hires, 'Hi-Res', ax, print_stats=do_stats, color='orange')
# Include T-dwarfs and Stars
ax[0].errorbar('T-Dwarfs',np.nanmedian(bds['M_H'])+8.69,yerr = np.nanstd(bds['M_H'])/np.sqrt(len(bds['M_H'])),color=cs[8],capsize=6,fmt='o',
markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[0].errorbar('T-Dwarfs',np.nanmedian(bds['M_H'])+8.69,yerr = np.nanstd(bds['M_H']),color=cs[8],capsize=6,fmt='o',
markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[0].errorbar('Stars',np.nanmedian(stars['O'])+8.69,yerr = np.nanstd(stars['O'])/np.sqrt(len(stars['O'])),color=cs[7],capsize=6,fmt='o',
markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[0].errorbar('Stars',np.nanmedian(stars['O'])+8.69,yerr = np.nanstd(stars['O']),color=cs[7],capsize=6,fmt='o',
markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[1].errorbar('T-Dwarfs',np.nanmedian(bds['C_O']),yerr = np.nanstd(bds['C_O'])/np.sqrt(len(bds['C_O'])),color=cs[8],capsize=6,fmt='o',
markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[1].errorbar('T-Dwarfs',np.nanmedian(bds['C_O']),yerr = np.nanstd(bds['C_O']),color=cs[8],capsize=6,fmt='o',
markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
# Now include C/O of stars from Hypatia
# We need to convert C and O relative to solar to absolute
aspund09_co = 10**8.43/10**8.69
ax[1].errorbar('Stars',np.nanmedian(10**stars['C']/10**stars['O'])*aspund09_co,
yerr = np.nanstd(aspund09_co*10**stars['C']/10**stars['O'])/np.sqrt(len(stars['O'])),
color=cs[7],capsize=6,fmt='o',markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
ax[1].errorbar('Stars',np.nanmedian(10**stars['C']/10**stars['O'])*aspund09_co,
yerr = np.nanstd(aspund09_co*10**stars['C']/10**stars['O']),
color=cs[7],capsize=6,fmt='o',markeredgecolor='k',markeredgewidth=0.5,linewidth=2)
# Plot range of solar values
ax[0].hlines(8.73,-2,12,'k',linestyle='--',label='Lodders+10')
ax[0].hlines(8.76,-2,12,'k',linestyle='-',label='Lodders+25')
ax[0].hlines(8.69,-2,12,'k',linestyle=':',label='Asplund+09/21')
ax[1].hlines(10**8.39/10**8.73,-2,12,'k',linestyle='--',label='Lodders+10')
ax[1].hlines(10**8.46/10**8.76,-2,12,'k',linestyle='-',label='Lodders+25')
ax[1].hlines(10**8.43/10**8.69,-2,12,'k',linestyle='-.',label='Asplund+09')
ax[1].hlines(10**8.46/10**8.69,-2,12,'k',linestyle=':',label='Asplund+21')
# Formatting
ax[0].set_ylabel('O/H',fontsize=15)
ax[1].set_ylabel('C/O',fontsize=15)
ax[1].legend(frameon=True,loc='lower left',fontsize=12)
ax[0].set_xticklabels(ax[0].get_xticklabels(),rotation=45,fontsize=15)
ax[1].set_xticklabels(ax[1].get_xticklabels(),rotation=45,fontsize=15)
ax[0].set_xlim(-0.5,10.5)
ax[1].set_ylim(0.0,1.0)
ax[1].set_xlim(-0.5,10.5)
ax[0].tick_params(labelsize=14)
ax[0].yaxis.set_ticks_position('both')
ax[0].xaxis.set_ticks_position('both')
ax[1].tick_params(labelsize=14)
ax[1].yaxis.set_ticks_position('both')
ax[1].xaxis.set_ticks_position('both')
ax[0].minorticks_on()
ax[1].minorticks_on()
plt.tight_layout()
plt.savefig('./paper_figs/metallicity_co_geometry.pdf')
\multicolumn{7}{c}{\textbf{Direct Spectroscopy (16 planets)}} \\
Average & $0.611 \pm 0.090$ & $0.824 \pm 0.496$ & $9.138 \pm 0.545$ & $8.870 \pm 0.610$ & $13.02 \pm 7.21$ & $100.5 \pm 1.9$ \\
Median & 0.560 & 0.359 & 9.123 & 8.789 & 11.85 & 100.0 \\
\multicolumn{7}{c}{\textbf{Eclipse Spectroscopy (18 planets)}} \\
Average & $0.773 \pm 0.187$ & $0.065 \pm 0.564$ & $9.070 \pm 0.815$ & $8.869 \pm 0.829$ & $2.70 \pm 2.73$ & $1678.9 \pm 773.3$ \\
Median & 0.705 & 0.394 & 9.094 & 8.788 & 1.72 & 1686.5 \\
\multicolumn{7}{c}{\textbf{Eclipse
No UHJ Spectroscopy (13 planets)}} \\
Average & $0.729 \pm 0.204$ & $0.020 \pm 0.545$ & $9.115 \pm 0.829$ & $8.929 \pm 0.864$ & $2.36 \pm 2.32$ & $1360.5 \pm 672.5$ \\
Median & 0.720 & 0.550 & 9.260 & 8.941 & 1.67 & 1411.0 \\
\multicolumn{7}{c}{\textbf{Transit Spectroscopy (15 planets)}} \\
Average & $0.705 \pm 0.427$ & $0.957 \pm 0.710$ & $9.546 \pm 0.727$ & $9.033 \pm 0.710$ & $1.47 \pm 2.12$ & $1518.0 \pm 613.5$ \\
Median & 0.350 & 0.930 & 9.593 & 8.786 & 0.78 & 1543.0 \\
\multicolumn{7}{c}{\textbf{Transit
No UHJ Spectroscopy (12 planets)}} \\
Average & $0.294 \pm 0.125$ & $0.885 \pm 0.813$ & $9.445 \pm 0.777$ & $9.055 \pm 0.713$ & $1.32 \pm 2.30$ & $1299.3 \pm 478.9$ \\
Median & 0.350 & 0.584 & 9.348 & 8.761 & 0.69 & 1371.0 \\
\multicolumn{7}{c}{\textbf{UHJs Spectroscopy (8 planets)}} \\
Average & $0.728 \pm 0.419$ & $0.860 \pm 0.523$ & $9.327 \pm 0.779$ & $8.800 \pm 0.709$ & $3.02 \pm 2.88$ & $2463.7 \pm 155.8$ \\
Median & 0.497 & 0.895 & 9.646 & 8.737 & 1.82 & 2459.0 \\
\multicolumn{7}{c}{\textbf{1-3um Spectroscopy (2 planets)}} \\
Average & $0.815 \pm 0.032$ & $0.533 \pm 0.606$ & $9.281 \pm 0.579$ & $9.127 \pm 0.646$ & $5.68 \pm 4.52$ & $2476.5 \pm 27.5$ \\
Median & 0.710 & 0.626 & 9.281 & 9.127 & 5.68 & 2476.5 \\
\multicolumn{7}{c}{\textbf{3-5um Spectroscopy (18 planets)}} \\
Average & $0.943 \pm 0.132$ & $0.762 \pm 0.828$ & $9.473 \pm 0.809$ & $9.119 \pm 0.856$ & $1.05 \pm 0.93$ & $1451.2 \pm 563.6$ \\
Median & 0.500 & 0.641 & 9.477 & 8.973 & 0.95 & 1585.5 \\
\multicolumn{7}{c}{\textbf{Hi-Res Spectroscopy (16 planets)}} \\
Average & $0.553 \pm 0.063$ & $0.057 \pm 0.534$ & $8.710 \pm 0.749$ & $8.502 \pm 0.711$ & $4.98 \pm 6.27$ & $1739.4 \pm 763.1$ \\
Median & 0.635 & -0.190 & 8.430 & 8.341 & 1.89 & 1691.0 \\
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3604463298.py:178: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax[0].set_xticklabels(ax[0].get_xticklabels(),rotation=45,fontsize=15)
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_45813/3604463298.py:179: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax[1].set_xticklabels(ax[1].get_xticklabels(),rotation=45,fontsize=15)

[12]:
# C/O temp
# If low transiting C/O is methane depletion...
fig, ax = plt.subplots(figsize=(6, 5))
pop_plot(fig,ax,'T_eq','C/O',plot_direct=False,
axis1_label='Equilibrium Temperature [K]')
plt.savefig('./paper_figs/temp_co.pdf')

[13]:
# Metallicity temp
# If low transiting C/O is methane depletion...
fig, ax = plt.subplots(figsize=(6.0, 5))
pop_plot(fig,ax,'T_eq','Metallicity',plot_direct=False,
axis1_label='Equilibrium Temperature [K]')
plt.savefig('./paper_figs/temp_met.pdf')
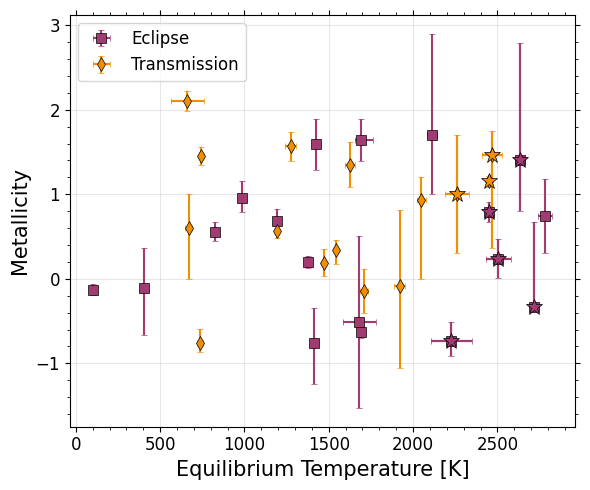
Metallicity & CO Statistical Tests
Correlations
[14]:
# Define weighted correlation tests
from scipy import stats
def weighted_correlation(x, y, sigma_x, sigma_y, verbose=False):
"""Calculate weighted Pearson correlation coefficient with uncertainties in both x and y"""
# Combined weights from both uncertainties
weights = 1 / (sigma_x**2 + sigma_y**2)
# Weighted means
x_mean = np.average(x, weights=weights)
y_mean = np.average(y, weights=weights)
# Weighted covariance and variances
cov = np.average((x - x_mean) * (y - y_mean), weights=weights)
var_x = np.average((x - x_mean)**2, weights=weights)
var_y = np.average((y - y_mean)**2, weights=weights)
# Correlation coefficient
cc = cov / np.sqrt(var_x * var_y)
if verbose:
print(cc)
return cc
def wrap_weighted_correlation(d,v1='Metallicity',v2='C/O'):
wc = weighted_correlation(d[v1],d[v2],
np.max([d[f'{v1} Lower'].values,d[f'{v1} Upper'].values],axis=0),
np.max([d[f'{v2} Lower'].values,d[f'{v2} Upper'].values],axis=0))
return wc
[15]:
# Metallicity versus C/O
print('Pearson CC Metallicity versus C/O: data, direct, emission, transit:')
display(stats.pearsonr(data['Metallicity'],data['C/O']))
display(stats.pearsonr(direct['Metallicity'],direct['C/O']))
display(stats.pearsonr(emission['Metallicity'],emission['C/O']))
display(stats.pearsonr(transit['Metallicity'],transit['C/O']))
print('--')
print('Weighted CC Metallicity versus C/O: data, direct, emission, transit:')
display(weighted_correlation(data['Metallicity'],data['C/O'],
np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0),
np.max([data['C/O Lower'].values,data['C/O Upper'].values],axis=0)))
display(weighted_correlation(direct['Metallicity'],direct['C/O'],
np.max([direct['Metallicity Lower'].values,direct['Metallicity Upper'].values],axis=0),
np.max([direct['C/O Lower'].values,direct['C/O Upper'].values],axis=0)))
display(weighted_correlation(emission['Metallicity'],emission['C/O'],
np.max([emission['Metallicity Lower'].values,emission['Metallicity Upper'].values],axis=0),
np.max([emission['C/O Lower'].values,emission['C/O Upper'].values],axis=0)))
display(weighted_correlation(transit['Metallicity'],transit['C/O'],
np.max([transit['Metallicity Lower'].values,transit['Metallicity Upper'].values],axis=0),
np.max([transit['C/O Lower'].values,transit['C/O Upper'].values],axis=0)))
Pearson CC Metallicity versus C/O: data, direct, emission, transit:
PearsonRResult(statistic=-0.013964296535937832, pvalue=0.9113909131915993)
PearsonRResult(statistic=0.6405768421023071, pvalue=0.007508049261887619)
PearsonRResult(statistic=0.16209677980002138, pvalue=0.5204719148285988)
PearsonRResult(statistic=-0.39424649091285213, pvalue=0.1459127592394487)
--
Weighted CC Metallicity versus C/O: data, direct, emission, transit:
0.28797775474405374
0.6229019517669526
0.4261101561877167
0.029766884481706887
[16]:
# Teq versus C/O
print('Pearson CC Teq versus C/O: emission, transit:')
display(stats.pearsonr(emission['T_eq'],emission['C/O']))
display(stats.pearsonr(transit['T_eq'],transit['C/O']))
print('--')
print('Weighted CC Teq versus C/O: emission, transit:')
display(weighted_correlation(emission['T_eq'],emission['C/O'],
np.max([emission['T_eq Lower'].values,emission['T_eq Upper'].values],axis=0),
np.max([emission['C/O Lower'].values,emission['C/O Upper'].values],axis=0)))
display(weighted_correlation(transit['T_eq'],transit['C/O'],
np.max([transit['T_eq Lower'].values,transit['T_eq Upper'].values],axis=0),
np.max([transit['C/O Lower'].values,transit['C/O Upper'].values],axis=0)))
Pearson CC Teq versus C/O: emission, transit:
PearsonRResult(statistic=0.22019578716672644, pvalue=0.3799482827121262)
PearsonRResult(statistic=-0.11813616594638135, pvalue=0.674982546425338)
--
Weighted CC Teq versus C/O: emission, transit:
0.9620219472463741
0.4101054171440646
[17]:
# Teq versus Metallicity
print('Pearson CC Teq versus Metallicity: emission, transit:')
display(stats.pearsonr(emission['T_eq'],emission['Metallicity']))
display(stats.pearsonr(transit['T_eq'],transit['Metallicity']))
print('--')
print('Weighted CC Teq versus Metallicity: emission, transit:')
#wrap_weighted_correlation(data)
display(weighted_correlation(emission['T_eq'],emission['Metallicity'],
np.max([emission['T_eq Lower'].values,emission['T_eq Upper'].values],axis=0),
np.max([emission['Metallicity Lower'].values,emission['Metallicity Upper'].values],axis=0)))
display(weighted_correlation(transit['T_eq'],transit['Metallicity'],
np.max([transit['T_eq Lower'].values,transit['T_eq Upper'].values],axis=0),
np.max([transit['Metallicity Lower'].values,transit['Metallicity Upper'].values],axis=0)))
Pearson CC Teq versus Metallicity: emission, transit:
PearsonRResult(statistic=0.13952504176937403, pvalue=0.5808316118170909)
PearsonRResult(statistic=0.05664763617958711, pvalue=0.8410727165796158)
--
Weighted CC Teq versus Metallicity: emission, transit:
-0.16821920576265195
0.4863353999169412
C/O KS Tests
[18]:
from scipy.stats import distributions
from scipy.stats import kstest
#see https://stackoverflow.com/questions/40044375/how-to-calculate-the-kolmogorov-smirnov-statistic-between-two-weighted-samples
def ks_weighted(data1, data2, wei1, wei2, alternative='two-sided'):
ix1 = np.argsort(data1)
ix2 = np.argsort(data2)
data1 = data1[ix1]
data2 = data2[ix2]
wei1 = wei1[ix1]
wei2 = wei2[ix2]
data = np.concatenate([data1, data2])
cwei1 = np.hstack([0, np.cumsum(wei1)/sum(wei1)])
cwei2 = np.hstack([0, np.cumsum(wei2)/sum(wei2)])
cdf1we = cwei1[np.searchsorted(data1, data, side='right')]
cdf2we = cwei2[np.searchsorted(data2, data, side='right')]
d = np.max(np.abs(cdf1we - cdf2we))
# calculate p-value
n1 = data1.shape[0]
n2 = data2.shape[0]
m, n = sorted([float(n1), float(n2)], reverse=True)
en = m * n / (m + n)
if alternative == 'two-sided':
prob = distributions.kstwo.sf(d, np.round(en))
else:
z = np.sqrt(en) * d
# Use Hodges' suggested approximation Eqn 5.3
# Requires m to be the larger of (n1, n2)
expt = -2 * z**2 - 2 * z * (m + 2*n)/np.sqrt(m*n*(m+n))/3.0
prob = np.exp(expt)
return d, prob
print('Test to show weighted and unweighted agree - use asymp p-val calc')
display(ks_weighted(transit['C/O'].values,direct['C/O'].values,
np.ones(len(transit)),np.ones(len(direct)))[1])
display(kstest(transit['C/O'],direct['C/O'],method='asymp')[1])
Test to show weighted and unweighted agree - use asymp p-val calc
0.010916465714889769
0.010916465714889769
[19]:
# planets vs. stars
# Can only do unweighted b/c of stellar weights??
stars['C/O'] = (10**stars['C']/10**stars['O'])*aspund09_co
display(kstest(data['C/O'],stars['C/O'].dropna(),method='asymp'))
KstestResult(statistic=0.3292360221937687, pvalue=6.568675759987819e-06, statistic_location=0.5754399373371571, statistic_sign=-1)
[20]:
#KS tests
print('---Unweighted---')
print('Transit versus Direct')
display(kstest(transit['C/O'],direct['C/O'],method='asymp'))
print('Emission versus Direct')
display(kstest(emission['C/O'],direct['C/O'],method='asymp'))
print('Transit versus Emission')
display(kstest(emission['C/O'],transit['C/O'],method='asymp'))
print('Transit (no UHJs) versus Direct')
display(kstest(transit_nouhj['C/O'],data['C/O'],method='asymp'))
print('---Weighted---')
print('Transit versus Direct')
display(ks_weighted(transit['C/O'].values,direct['C/O'].values,
1/(np.max([transit['C/O Lower'].values,transit['C/O Upper'].values],axis=0))**2,
1/np.max([direct['C/O Lower'].values,direct['C/O Upper'].values],axis=0)**2))
print('Emission versus Direct')
display(ks_weighted(emission['C/O'].values,direct['C/O'].values,
1/np.max([emission['C/O Lower'].values,emission['C/O Upper'].values],axis=0)**2,
1/np.max([direct['C/O Lower'].values,direct['C/O Upper'].values],axis=0)**2))
print('Transit versus Emission')
display(ks_weighted(transit['C/O'].values,emission['C/O'].values,
1/np.max([transit['C/O Lower'].values,transit['C/O Upper'].values],axis=0)**2,
1/np.max([emission['C/O Lower'].values,emission['C/O Upper'].values],axis=0)**2))
print('Transit (no UHJs) versus Direct')
display(ks_weighted(transit_nouhj['C/O'].values,direct['C/O'].values,
1/np.max([transit_nouhj['C/O Lower'].values,transit_nouhj['C/O Upper'].values],axis=0)**2,
1/np.max([direct['C/O Lower'].values,direct['C/O Upper'].values],axis=0)**2))
---Unweighted---
Transit versus Direct
KstestResult(statistic=0.5375, pvalue=0.010916465714889769, statistic_location=0.35, statistic_sign=1)
Emission versus Direct
KstestResult(statistic=0.4236111111111111, pvalue=0.08117625333702128, statistic_location=0.66, statistic_sign=-1)
Transit versus Emission
KstestResult(statistic=0.5333333333333334, pvalue=0.01187611196535396, statistic_location=0.585, statistic_sign=-1)
Transit (no UHJs) versus Direct
KstestResult(statistic=0.42234848484848486, pvalue=0.012834670132515047, statistic_location=0.585, statistic_sign=1)
---Weighted---
Transit versus Direct
(0.7072116351573585, 0.00015060630669413172)
Emission versus Direct
(0.6427173229112506, 0.0009552228173997642)
Transit versus Emission
(0.7072116351573585, 0.00015060630669413172)
Transit (no UHJs) versus Direct
(0.9062119853595603, 1.1973158621674008e-08)
Metallicity KS Tests
[21]:
# planets vs. stars
# Can only do unweighted b/c of stellar weights??
display(kstest(data['Metallicity'],stars['Fe'].dropna()))
display(ks_weighted(data['Metallicity'].values,stars['Fe'].dropna().values,
1/np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)**2,
np.ones(len(stars['Fe'].dropna()))))
KstestResult(statistic=0.5627575757575758, pvalue=6.300939371659787e-19, statistic_location=0.33, statistic_sign=-1)
(0.6682059498627333, 8.216470695742154e-28)
[22]:
#KS tests
from scipy.stats import kstest
print('---Unweighted---')
print('Transit versus Direct')
display(kstest(transit['Metallicity'],direct['Metallicity']))
print('Direct versus Eclipse')
display(kstest(emission['Metallicity'],direct['Metallicity']))
print('Transit versus Eclipse')
display(kstest(emission['Metallicity'],transit['Metallicity']))
print('Transit (nouhj) versus All')
display(kstest(transit_nouhj['Metallicity'],data['Metallicity']))
print('Transit versus All')
display(kstest(transit['Metallicity'],data['Metallicity']))
print('Eclipse versus All')
display(kstest(emission['Metallicity'],data['Metallicity']))
print('Eclipse (nouhj) versus All')
display(kstest(emission_nouhj['Metallicity'],data['Metallicity']))
print('---Weighted---')
print('Transit versus Direct')
display(ks_weighted(transit['Metallicity'].values,direct['Metallicity'].values,
1/np.max([transit['Metallicity Lower'].values,transit['Metallicity Upper'].values],axis=0)**2,
1/np.max([direct['Metallicity Lower'].values,direct['Metallicity Upper'].values],axis=0)**2))
print('Direct versus Eclipse')
display(ks_weighted(emission['Metallicity'].values,direct['Metallicity'].values,
1/np.max([emission['Metallicity Lower'].values,emission['Metallicity Upper'].values],axis=0)**2,
1/np.max([direct['Metallicity Lower'].values,direct['Metallicity Upper'].values],axis=0)**2))
print('Transit versus Eclipse')
display(ks_weighted(transit['Metallicity'].values,emission['Metallicity'].values,
1/np.max([transit['Metallicity Lower'].values,transit['Metallicity Upper'].values],axis=0)**2,
1/np.max([emission['Metallicity Lower'].values,emission['Metallicity Upper'].values],axis=0)**2))
print('Transit (nouhj) versus All')
display(ks_weighted(transit_nouhj['Metallicity'].values,data['Metallicity'].values,
1/np.max([transit_nouhj['Metallicity Lower'].values,transit_nouhj['Metallicity Upper'].values],axis=0)**2,
1/np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)**2))
print('Transit versus All')
display(ks_weighted(transit['Metallicity'].values,data['Metallicity'].values,
1/np.max([transit['Metallicity Lower'].values,transit['Metallicity Upper'].values],axis=0)**2,
1/np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)**2))
print('Direct versus All')
display(ks_weighted(direct['Metallicity'].values,data['Metallicity'].values,
1/np.max([direct['Metallicity Lower'].values,direct['Metallicity Upper'].values],axis=0)**2,
1/np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)**2))
print('Eclipse versus All')
display(ks_weighted(emission['Metallicity'].values,data['Metallicity'].values,
1/np.max([emission['Metallicity Lower'].values,emission['Metallicity Upper'].values],axis=0)**2,
1/np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)**2))
print('Eclipse (nouhj) versus All')
display(ks_weighted(emission_nouhj['Metallicity'].values,data['Metallicity'].values,
1/np.max([emission_nouhj['Metallicity Lower'].values,emission_nouhj['Metallicity Upper'].values],axis=0)**2,
1/np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)**2))
---Unweighted---
Transit versus Direct
KstestResult(statistic=0.2916666666666667, pvalue=0.42629346134549484, statistic_location=0.54, statistic_sign=-1)
Direct versus Eclipse
KstestResult(statistic=0.2777777777777778, pvalue=0.4293158524103572, statistic_location=-0.33, statistic_sign=1)
Transit versus Eclipse
KstestResult(statistic=0.25555555555555554, pvalue=0.5736808272434241, statistic_location=-0.11, statistic_sign=1)
Transit (nouhj) versus All
KstestResult(statistic=0.16477272727272727, pvalue=0.8130717670668356, statistic_location=-0.17, statistic_sign=-1)
Transit versus All
KstestResult(statistic=0.22727272727272727, pvalue=0.4821048957740845, statistic_location=0.55, statistic_sign=-1)
Eclipse versus All
KstestResult(statistic=0.1414141414141414, pvalue=0.902997004829324, statistic_location=-0.33, statistic_sign=1)
Eclipse (nouhj) versus All
KstestResult(statistic=0.20095693779904306, pvalue=0.5133585327036325, statistic_location=-0.11, statistic_sign=1)
---Weighted---
Transit versus Direct
(0.305294586723762, 0.3691800454471108)
Direct versus Eclipse
(0.6184583866087447, 0.0017776670392841256)
Transit versus Eclipse
(0.6080472113228086, 0.002293123054953894)
Transit (nouhj) versus All
(0.2664885800746464, 0.263817706785329)
Transit versus All
(0.31479056536667005, 0.14828438020084733)
Direct versus All
(0.24774593219207436, 0.34388271291168093)
Eclipse versus All
(0.3876742339838617, 0.02098430995441003)
Eclipse (nouhj) versus All
(0.4355717930387687, 0.004178134718310855)
[23]:
# 2D KS
#import ndtest
#P, D = ndtest.ks2d2s(transit['C/O'].values, transit['Metallicity'].values,
emission['C/O'].values, emission['Metallicity'].values, extra=True)
#print(P,D)
#P, D = ndtest.ks2d2s(transit['C/O'].values, transit['Metallicity'].values,
direct['C/O'].values, direct['Metallicity'].values, extra=True)
#print(P,D)
#P, D = ndtest.ks2d2s(direct['C/O'].values, direct['Metallicity'].values,
emission['C/O'].values, emission['Metallicity'].values, extra=True)
#print(P,D)
0.02285733851666528 0.5166666666666667
0.011270580115818643 0.56875
0.03661180335504245 0.4826388888888889
Mass-Composition Correlation Tests
[24]:
print('Pearson CC Mass versus C/O: data, direct, emission, transit:')
print('---Unweighted---')
print('All')
display(stats.pearsonr(data['Mass'],data['C/O']))
print('Direct')
display(stats.pearsonr(direct['Mass'],direct['C/O']))
print('Eclipse')
display(stats.pearsonr(emission['Mass'],emission['C/O']))
print('Transit')
display(stats.pearsonr(transit['Mass'],transit['C/O']))
print('---Weighted Coefficients (not Pvalues)---')
print('All')
display(weighted_correlation(data['Mass'],data['C/O'],
np.ones(len(data['Mass'])),
np.max([data['C/O Lower'].values,data['C/O Upper'].values],axis=0)))
print('Direct')
display(weighted_correlation(direct['Mass'],direct['C/O'],
np.ones(len(direct['Mass'])),
np.max([direct['C/O Lower'].values,direct['C/O Upper'].values],axis=0)))
print('Direct No HR8799')
display(weighted_correlation(direct_nohr8799['Mass'],direct_nohr8799['C/O'],
np.ones(len(direct_nohr8799['Mass'])),
np.max([direct_nohr8799['C/O Lower'].values,direct_nohr8799['C/O Upper'].values],axis=0)))
print('Eclipse')
display(weighted_correlation(emission['Mass'],emission['C/O'],
np.ones(len(emission['Mass'])),
np.max([emission['C/O Lower'].values,emission['C/O Upper'].values],axis=0)))
print('Transit')
display(weighted_correlation(transit['Mass'],transit['C/O'],
np.ones(len(transit['Mass'])),
np.max([transit['C/O Lower'].values,transit['C/O Upper'].values],axis=0)))
Pearson CC Mass versus C/O: data, direct, emission, transit:
---Unweighted---
All
PearsonRResult(statistic=0.01604223520875822, pvalue=0.8982710068045661)
Direct
PearsonRResult(statistic=0.017497217154245483, pvalue=0.9487187648127204)
Eclipse
PearsonRResult(statistic=-0.3611613117200738, pvalue=0.14088237034975143)
Transit
PearsonRResult(statistic=-0.062147557254192076, pvalue=0.8258505462205231)
---Weighted Coefficients (not Pvalues)---
All
0.020829836583343985
Direct
0.011180010818847534
Direct No HR8799
0.2716153613615166
Eclipse
-0.3653973780283877
Transit
-0.052119346609028075
[25]:
print('Pearson CC Mass versus Metallicity: data, direct, emission, transit:')
print('---Unweighted---')
print('All')
display(stats.pearsonr(data['Mass'],data['Metallicity']))
print('Direct')
display(stats.pearsonr(direct['Mass'],direct['Metallicity']))
print('Eclipse')
display(stats.pearsonr(emission['Mass'],emission['Metallicity']))
print('Transit')
display(stats.pearsonr(transit['Mass'],transit['Metallicity']))
print('---Weighted Coefficients (not Pvalues)---')
print('All')
display(weighted_correlation(data['Mass'],data['Metallicity'],
np.ones(len(data['Mass'])),
np.max([data['Metallicity Lower'].values,data['Metallicity Upper'].values],axis=0)))
print('Direct')
display(weighted_correlation(direct['Mass'],direct['Metallicity'],
np.ones(len(direct['Mass'])),
np.max([direct['Metallicity Lower'].values,direct['Metallicity Upper'].values],axis=0)))
print('Direct No HR8799')
display(weighted_correlation(direct_nohr8799['Mass'],direct_nohr8799['Metallicity'],
np.ones(len(direct_nohr8799['Mass'])),
np.max([direct_nohr8799['Metallicity Lower'].values,direct_nohr8799['Metallicity Upper'].values],axis=0)))
print('Eclipse')
display(weighted_correlation(emission['Mass'],emission['Metallicity'],
np.ones(len(emission['Mass'])),
np.max([emission['Metallicity Lower'].values,emission['Metallicity Upper'].values],axis=0)))
print('Transit')
display(weighted_correlation(transit['Mass'],transit['Metallicity'],
np.ones(len(transit['Mass'])),
np.max([transit['Metallicity Lower'].values,transit['Metallicity Upper'].values],axis=0)))
Pearson CC Mass versus Metallicity: data, direct, emission, transit:
---Unweighted---
All
PearsonRResult(statistic=-0.21471841745908585, pvalue=0.0833969415460411)
Direct
PearsonRResult(statistic=-0.4352904938817366, pvalue=0.09195537151044374)
Eclipse
PearsonRResult(statistic=-0.43267290747770776, pvalue=0.07291038332355068)
Transit
PearsonRResult(statistic=-0.3352155150829301, pvalue=0.22194149282066594)
---Weighted Coefficients (not Pvalues)---
All
-0.20106386496302864
Direct
-0.49159819788765846
Direct No HR8799
-0.42817930486335526
Eclipse
-0.3946300723318043
Transit
-0.3004807833305506
C/O versus Mass
[26]:
#fig, ax = plt.subplots(figsize=(9, 6))
# Mass C/O
# If low transiting C/O is methane depletion...
fig, ax = plt.subplots(figsize=(8, 6))
pop_plot(fig,ax,'Mass','C/O',plot_direct=True,
axis1_label='Mass [M$_J$]')
#plt.gca().set_xscale('log')
plt.xlim(-1,30)
plt.savefig('./paper_figs/mass_co_geometry.pdf')
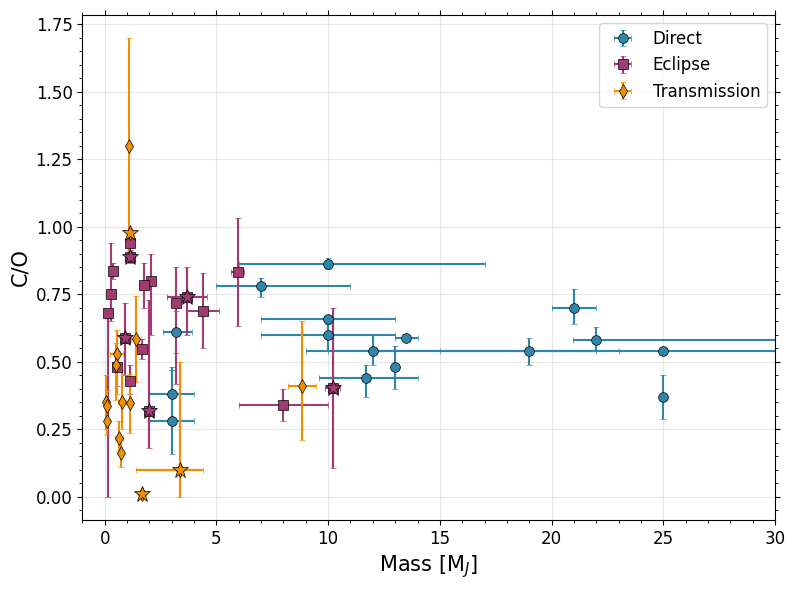
Stellar Property vs. Metallicity Plots
[27]:
# Planet Metallcity vs. Stellar Metallicity
#Custom plotting this one b/c we want to filter bad measurements
fig, ax = plt.subplots(figsize=(6, 5))
for d, label, marker, color in zip([direct, emission, transit],
['Direct', 'Eclipse', 'Transmission','UHJ'],
['o', 's', 'd', '*'],
['#2E86AB', '#A23B72', '#F18F01', 'grey']):
# If stellar metallicity is -99, that means it doesn't have a main sequence host!
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
#Same for mass
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
ax.errorbar(d['Stellar Metallicity'], d['Metallicity'],
xerr=[d['Stellar Metallicity Lower'], d['Stellar Metallicity Upper']],
yerr=[d['Metallicity Lower'], d['Metallicity Upper']],
fmt=marker, label=label, color=color,
markersize=7, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
if row['Stellar Metallicity'] == -99:
continue
if row['Stellar Metallicity'] == 0.0:
continue
ax.errorbar(row['Stellar Metallicity'], row['Metallicity'],
xerr=[[row['Stellar Metallicity Lower']], [row['Stellar Metallicity Upper']]],
yerr=[[row['Metallicity Lower']], [row['Metallicity Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
#ax.set_xscale('log')
ax.set_xlabel('Stellar Metallicity [M/H]', fontsize=15)
ax.set_ylabel('Planet Metallicity [M/H]', fontsize=15)
#ax.legend(frameon=True, fancybox=True, shadow=False,loc='upper left')
ax.grid(True, alpha=0.3)
ax.minorticks_on()
plt.tight_layout()
plt.savefig('./paper_figs/metallicity_metallicity.pdf')
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:12: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:16: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:20: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:24: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:12: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:16: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:20: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:24: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:12: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:16: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:20: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/1782682592.py:24: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
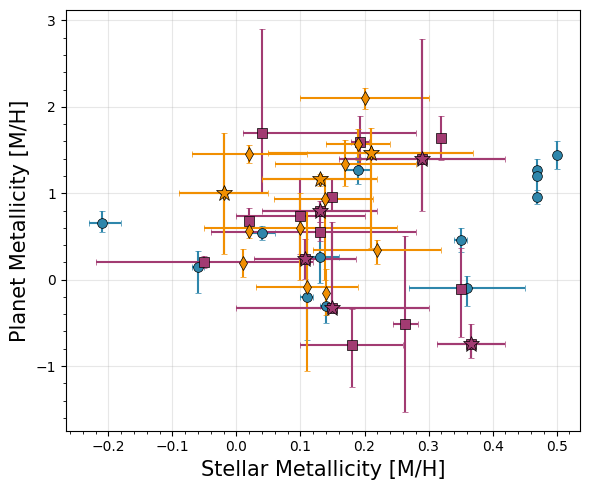
[28]:
# Planet C/O vs. Stellar Metallicity
#Custom plotting this one b/c we want to filter bad measurements
fig, ax = plt.subplots(figsize=(6, 5))
for d, label, marker, color in zip([direct, emission, transit],
['Direct', 'Eclipse', 'Transmission','UHJ'],
['o', 's', 'd', '*'],
['#2E86AB', '#A23B72', '#F18F01', 'grey']):
# If stellar metallicity is -99, that means it doesn't have a main sequence host!
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
#Same for mass
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
ax.errorbar(d['Stellar Metallicity'], d['C/O'],
xerr=[d['Stellar Metallicity Lower'], d['Stellar Metallicity Upper']],
yerr=[d['C/O Lower'], d['C/O Upper']],
fmt=marker, label=label, color=color,
markersize=7, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
if row['Stellar Metallicity'] == -99:
continue
if row['Stellar Metallicity'] == 0.0:
continue
ax.errorbar(row['Stellar Metallicity'], row['C/O'],
xerr=[[row['Stellar Metallicity Lower']], [row['Stellar Metallicity Upper']]],
yerr=[[row['C/O Lower']], [row['C/O Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
#ax.set_xscale('log')
ax.set_xlabel('Stellar Metallicity [M/H]', fontsize=15)
ax.set_ylabel('Planet C/O', fontsize=15)
#ax.legend(frameon=True, fancybox=True, shadow=False,loc='upper left')
ax.grid(True, alpha=0.3)
ax.minorticks_on()
plt.tight_layout()
plt.savefig('./paper_figs/co_stellarmetallicity.pdf')
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:12: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:16: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:20: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:24: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:12: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:16: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:20: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:24: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:12: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:16: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:20: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3468103133.py:24: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
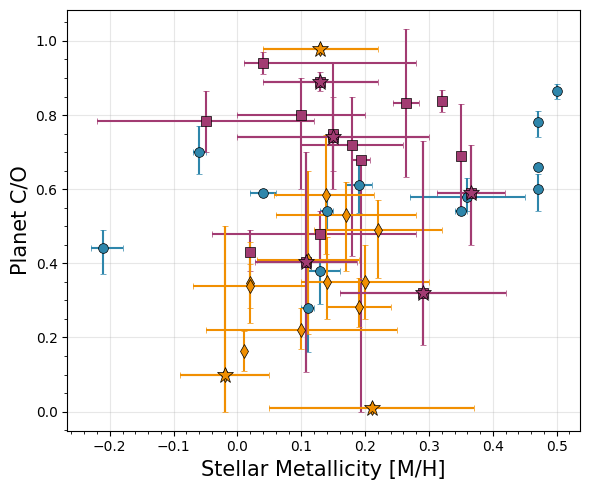
[29]:
# Planet Metallicity vs. Stellar Mass
fig, ax = plt.subplots(figsize=(6, 5))
for d, label, marker, color in zip([direct, emission, transit],
['Direct', 'Eclipse', 'Transmission','UHJ'],
['o', 's', 'd', '*'],
['#2E86AB', '#A23B72', '#F18F01', 'grey']):
# If stellar metallicity is -99, that means it doesn't have a main sequence host!
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
#Same for mass
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
ax.errorbar(d['Stellar Mass'], d['Metallicity'],
xerr=[d['Stellar Mass Lower'], d['Stellar Mass Upper']],
yerr=[d['Metallicity Lower'], d['Metallicity Upper']],
fmt=marker, label=label, color=color,
markersize=7, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
if row['Stellar Metallicity'] == -99:
continue
if row['Stellar Metallicity'] == 0.0:
continue
ax.errorbar(row['Stellar Mass'], row['Metallicity'],
xerr=[[row['Stellar Mass Lower']], [row['Stellar Mass Upper']]],
yerr=[[row['Metallicity Lower']], [row['Metallicity Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
#ax.set_xscale('log')
ax.set_xlabel('Stellar Mass [Solar masses]', fontsize=15)
ax.set_ylabel('Planet Metallicity [M/H]', fontsize=15)
ax.legend(frameon=True, fancybox=True, shadow=False,loc='upper right')
ax.grid(True, alpha=0.3)
ax.minorticks_on()
plt.tight_layout()
plt.savefig('./paper_figs/stellarmass_metallicity.pdf')
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:9: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:13: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:17: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:21: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:9: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:13: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:17: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:21: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:9: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:13: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:17: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:21: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3704831077.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
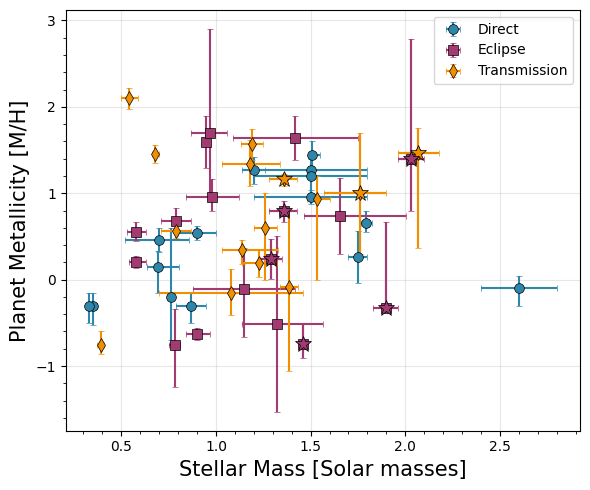
[30]:
# Planet C/O vs. Stellar Mass
fig, ax = plt.subplots(figsize=(6, 5))
for d, label, marker, color in zip([direct, emission, transit],
['Direct', 'Eclipse', 'Transmission','UHJ'],
['o', 's', 'd', '*'],
['#2E86AB', '#A23B72', '#F18F01', 'grey']):
# If stellar metallicity is -99, that means it doesn't have a main sequence host!
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
#Same for mass
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
# If stellar metallicity is exactly 0.0, that means we don't have a measurement and assume solar... let's ignore those
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
ax.errorbar(d['Stellar Mass'], d['C/O'],
xerr=[d['Stellar Mass Lower'], d['Stellar Mass Upper']],
yerr=[d['C/O Lower'], d['C/O Upper']],
fmt=marker, label=label, color=color,
markersize=7, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
if row['Stellar Metallicity'] == -99:
continue
if row['Stellar Metallicity'] == 0.0:
continue
ax.errorbar(row['Stellar Mass'], row['C/O'],
xerr=[[row['Stellar Mass Lower']], [row['Stellar Mass Upper']]],
yerr=[[row['C/O Lower']], [row['C/O Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
#ax.set_xscale('log')
ax.set_xlabel('Stellar Mass [Solar masses]', fontsize=15)
ax.set_ylabel('Planet C/O', fontsize=15)
#ax.legend(frameon=True, fancybox=True, shadow=False,loc='upper right')
ax.grid(True, alpha=0.3)
ax.minorticks_on()
plt.tight_layout()
plt.savefig('./paper_figs/stellarmass_co.pdf')
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:9: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:13: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:17: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:21: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:9: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:13: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:17: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:21: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:9: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:10: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:11: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:13: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity'].iloc[np.where(d['Stellar Metallicity'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:14: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Upper'].iloc[np.where(d['Stellar Metallicity Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:15: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Metallicity Lower'].iloc[np.where(d['Stellar Metallicity Lower'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:17: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:18: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:19: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == -99)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:21: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass'].iloc[np.where(d['Stellar Mass'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:22: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Upper'].iloc[np.where(d['Stellar Mass Upper'] == 0.0)[0]] = np.nan
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2445045271.py:23: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
d['Stellar Mass Lower'].iloc[np.where(d['Stellar Mass Lower'] == 0.0)[0]] = np.nan
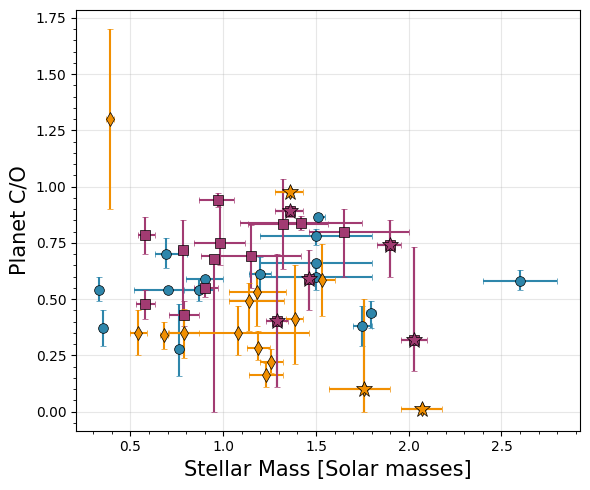
Stellar Correlations
I’m not sure how to deal with the stellar metallicity and mass uncertainties because many are missing. Let’s keep unweighted for now. ### Stellar metallicity versus Planet metallicity
[31]:
from scipy import stats
display(stats.pearsonr(transit['Stellar Metallicity'].dropna(),transit.dropna(subset=['Stellar Metallicity'])['Metallicity']))
display(stats.pearsonr(emission['Stellar Metallicity'].dropna(),emission.dropna(subset=['Stellar Metallicity'])['Metallicity']))
display(stats.pearsonr(direct['Stellar Metallicity'].dropna(),direct.dropna(subset=['Stellar Metallicity'])['Metallicity']))
display(stats.pearsonr(data['Stellar Metallicity'].dropna(),data.dropna(subset=['Stellar Metallicity'])['Metallicity']))
PearsonRResult(statistic=0.28287791960527015, pvalue=0.3271040020337429)
PearsonRResult(statistic=-0.184878106324994, pvalue=0.493046811049206)
PearsonRResult(statistic=0.4898049934495137, pvalue=0.08931398516289683)
PearsonRResult(statistic=0.10364735322511971, pvalue=0.40756830245359443)
Stellar metallicity versus Planet C/O
[32]:
from scipy import stats
display(stats.pearsonr(transit['Stellar Metallicity'].dropna(),transit.dropna(subset=['Stellar Metallicity'])['C/O']))
display(stats.pearsonr(emission['Stellar Metallicity'].dropna(),emission.dropna(subset=['Stellar Metallicity'])['C/O']))
display(stats.pearsonr(direct['Stellar Metallicity'].dropna(),direct.dropna(subset=['Stellar Metallicity'])['C/O']))
display(stats.pearsonr(direct_nohr8799['Stellar Metallicity'].dropna(),direct_nohr8799.dropna(subset=['Stellar Metallicity'])['C/O']))
display(stats.pearsonr(data['Stellar Metallicity'].dropna(),data.dropna(subset=['Stellar Metallicity'])['C/O']))
PearsonRResult(statistic=0.2322659676227221, pvalue=0.4242596853164645)
PearsonRResult(statistic=-0.1006723115297697, pvalue=0.7106608752856736)
PearsonRResult(statistic=0.528463494790637, pvalue=0.06336574285876743)
PearsonRResult(statistic=0.273496265681139, pvalue=0.3440810570481956)
PearsonRResult(statistic=0.11742954808199495, pvalue=0.3477160461870806)
Stellar Mass versus Planet metallicity
[33]:
from scipy import stats
display(stats.pearsonr(transit['Stellar Mass'].dropna(),transit.dropna(subset=['Stellar Mass'])['Metallicity']))
display(stats.pearsonr(emission['Stellar Mass'].dropna(),emission.dropna(subset=['Stellar Mass'])['Metallicity']))
display(stats.pearsonr(direct['Stellar Mass'].dropna(),direct.dropna(subset=['Stellar Mass'])['Metallicity']))
display(stats.pearsonr(data['Stellar Mass'].dropna(),data.dropna(subset=['Stellar Mass'])['Metallicity']))
PearsonRResult(statistic=0.181561924979298, pvalue=0.5172442724803548)
PearsonRResult(statistic=0.07138764199875626, pvalue=0.7854174883480484)
PearsonRResult(statistic=0.38353137311029917, pvalue=0.15818470613154015)
PearsonRResult(statistic=0.13298790386205964, pvalue=0.2871054484482557)
Stellar Mass versus Planet C/O
[34]:
from scipy import stats
display(stats.pearsonr(transit['Stellar Mass'].dropna(),transit.dropna(subset=['Stellar Mass'])['C/O']))
display(stats.pearsonr(emission['Stellar Mass'].dropna(),emission.dropna(subset=['Stellar Mass'])['C/O']))
display(stats.pearsonr(direct['Stellar Mass'].dropna(),direct.dropna(subset=['Stellar Mass'])['C/O']))
display(stats.pearsonr(data['Stellar Mass'].dropna(),data.dropna(subset=['Stellar Mass'])['C/O']))
PearsonRResult(statistic=-0.4819463782197407, pvalue=0.06887902557809111)
PearsonRResult(statistic=-0.045797326861969315, pvalue=0.8614451694612288)
PearsonRResult(statistic=0.22201775901534723, pvalue=0.4264536055036452)
PearsonRResult(statistic=0.11049689881198713, pvalue=0.3771075653157047)
Mass-Metallicity
There are two cells at the end with the functions used here. I don’t want to put them here because they’re long. I should put them in a separate script to import, but they’re useful to work with directly here.
Let’s first calculate with the metallicity as given, then calculate for O/H and C/H individually. For each, we’ll run dynesty to fit a line to the sample AND fit the scenario where there is no mass-metallicity realtionship, so we can compare evidences.
But first, let’s read in the Solar System data, b/c we’ll compare to that. For the Solar System, we take the atmospheric metallicities from Kreidberg et al. 2014b. These are measurements of CH4, so metallicity here is equal to [C/H]. We’ll use the solar C/O to convert to O/H BUT this may not be the case in reality as the Solar System planets may not have accreted C and O in equal proportion.
[37]:
# Input intervals (times solar)
metallicity_bounds = {
"Jupiter": (3.3, 5.5),
"Saturn": (9.5, 10.3),
"Neptune": (71, 100),
"Uranus": (67, 111)
}
# Build the DataFrame
rows = []
for planet, (low, high) in metallicity_bounds.items():
median = (low + high) / 2
log_median = np.log10(median)
log_low = np.log10(low)
log_high = np.log10(high)
err_lower = log_median - log_low
err_upper = log_high - log_median
rows.append({
"Planet": planet,
"Metallicity": log_median,
"Metallicity Lower": err_lower,
"Metallicity Upper": err_upper,
"O/H" : np.log10(median*10**8.69),
"O/H Lower": np.log10(median*10**8.69) - np.log10(low*10**8.69),
"O/H Upper": np.log10(high*10**8.69) - np.log10(median*10**8.69),
"C/H" : np.log10(median*10**8.43),
"C/H Lower": np.log10(median*10**8.43) - np.log10(low*10**8.43),
"C/H Upper": np.log10(high*10**8.43) - np.log10(median*10**8.43),
})
solar_system = pd.DataFrame(rows)
solar_system['Mass'] = [ 1.0, 568/1898, 86.8/1898, 102/ 1898]
solar_system['Mass Lower'] = [ 0,0,0,0]
solar_system['Mass Upper'] = [ 0,0,0,0]
Metallicity as given
[56]:
# Run the flat (no relationship) cases
results_direct_flat = mass_mh_dynesty_flat(direct, plot_it=False, xerrs=False, oh=False)
results_transit_flat = mass_mh_dynesty_flat(transit, plot_it=False, xerrs=False, oh=False)
results_emission_flat = mass_mh_dynesty_flat(emission, plot_it=False, xerrs=False, oh=False)
results_ss_flat = mass_mh_dynesty_flat(solar_system, plot_it=False, xerrs=False, oh=False)
Running nested sampling...
3978it [00:01, 2036.01it/s, +500 | bound: 5 | nc: 1 | ncall: 22058 | eff(%): 20.772 | loglstar: -inf < -203.746 < inf | logz: -209.342 +/- 0.099 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -209.34 ± 0.13
Number of likelihood evaluations: 3978
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 0.710 [0.680, 0.739] [0.030, 0.029]
Running nested sampling...
3796it [00:01, 1917.98it/s, +500 | bound: 5 | nc: 1 | ncall: 21179 | eff(%): 20.775 | loglstar: -inf < -200.582 < inf | logz: -205.814 +/- 0.095 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -205.81 ± 0.12
Number of likelihood evaluations: 3796
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 0.926 [0.886, 0.964] [0.040, 0.038]
Running nested sampling...
3931it [00:01, 1996.93it/s, +500 | bound: 5 | nc: 1 | ncall: 21718 | eff(%): 20.883 | loglstar: -inf < -215.753 < inf | logz: -221.256 +/- 0.097 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -221.26 ± 0.12
Number of likelihood evaluations: 3931
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 0.117 [0.086, 0.150] [0.032, 0.032]
Running nested sampling...
4240it [00:01, 2211.55it/s, +500 | bound: 6 | nc: 1 | ncall: 22459 | eff(%): 21.586 | loglstar: -inf < -99.398 < inf | logz: -105.517 +/- 0.104 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -105.52 ± 0.13
Number of likelihood evaluations: 4240
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 1.041 [1.024, 1.058] [0.017, 0.017]
[57]:
results_transit = mass_mh_dynesty(transit, plot_it=False, xerrs=False)
results_emission = mass_mh_dynesty(emission, plot_it=False, xerrs=False)
results_direct = mass_mh_dynesty(direct, plot_it=False, xerrs=False)
results_ss = mass_mh_dynesty(solar_system, plot_it=True, xerrs=False, oh=False)
Running nested sampling...
2422it [00:01, 908.05it/s, bound: 9 | nc: 25 | ncall: 24523 | eff(%): 9.876 | loglstar: -inf < -200.795 < inf | logz: -207.769 +/- 0.111 | dlogz: 90.719 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7092it [00:04, 1504.82it/s, +500 | bound: 35 | nc: 1 | ncall: 43869 | eff(%): 17.506 | loglstar: -inf < -111.576 < inf | logz: -123.404 +/- 0.146 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -123.40 ± 0.18
Number of likelihood evaluations: 7092
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.749 [-2.164, -1.439] [0.415, 0.311]
intercept (b) -0.286 [-0.749, 0.070] [0.462, 0.356]
cutoff (s) -0.513 [-0.638, -0.366] [0.125, 0.147]
Running nested sampling...
2752it [00:03, 381.36it/s, bound: 21 | nc: 29 | ncall: 32770 | eff(%): 8.398 | loglstar: -inf < -216.003 < inf | logz: -223.108 +/- 0.112 | dlogz: 68.497 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2805it [00:03, 223.85it/s, bound: 28 | nc: 558 | ncall: 38040 | eff(%): 7.374 | loglstar: -inf < -215.805 < inf | logz: -222.662 +/- 0.111 | dlogz: 67.943 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2844it [00:07, 74.29it/s, bound: 47 | nc: 82 | ncall: 51953 | eff(%): 5.474 | loglstar: -inf < -215.756 < inf | logz: -222.423 +/- 0.110 | dlogz: 67.624 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
8593it [00:10, 784.50it/s, +500 | bound: 80 | nc: 1 | ncall: 77523 | eff(%): 11.806 | loglstar: -inf < -142.271 < inf | logz: -157.108 +/- 0.163 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -157.11 ± 0.20
Number of likelihood evaluations: 8593
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.752 [-1.908, -1.594] [0.156, 0.158]
intercept (b) 0.290 [0.250, 0.328] [0.040, 0.038]
cutoff (s) 0.221 [0.208, 0.232] [0.013, 0.012]
Running nested sampling...
2630it [00:04, 271.66it/s, bound: 33 | nc: 73 | ncall: 42380 | eff(%): 6.206 | loglstar: -inf < -203.760 < inf | logz: -210.176 +/- 0.108 | dlogz: 67.937 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
5956it [00:07, 747.54it/s, +500 | bound: 57 | nc: 1 | ncall: 60438 | eff(%): 10.771 | loglstar: -inf < -136.788 < inf | logz: -146.340 +/- 0.131 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -146.34 ± 0.16
Number of likelihood evaluations: 5956
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.703 [-1.855, -1.557] [0.152, 0.146]
intercept (b) 2.509 [2.350, 2.667] [0.159, 0.158]
cutoff (s) 3.096 [1.980, 4.407] [1.116, 1.311]
Running nested sampling...
2782it [00:02, 689.30it/s, bound: 20 | nc: 7 | ncall: 32119 | eff(%): 8.662 | loglstar: -inf < -99.614 < inf | logz: -107.659 +/- 0.120 | dlogz: 100.811 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
6289it [00:05, 1520.81it/s, bound: 52 | nc: 1 | ncall: 56227 | eff(%): 11.185 | loglstar: -inf < -1.645 < inf | logz: -12.112 +/- 0.137 | dlogz: 0.611 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7250it [00:06, 1096.75it/s, +500 | bound: 60 | nc: 1 | ncall: 62740 | eff(%): 12.452 | loglstar: -inf < 0.280 < inf | logz: -11.880 +/- 0.144 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -11.88 ± 0.17
Number of likelihood evaluations: 7250
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.127 [-1.210, -1.043] [0.083, 0.084]
intercept (b) 0.412 [0.360, 0.462] [0.051, 0.051]
cutoff (s) 1.729 [-0.169, 3.844] [1.899, 2.114]
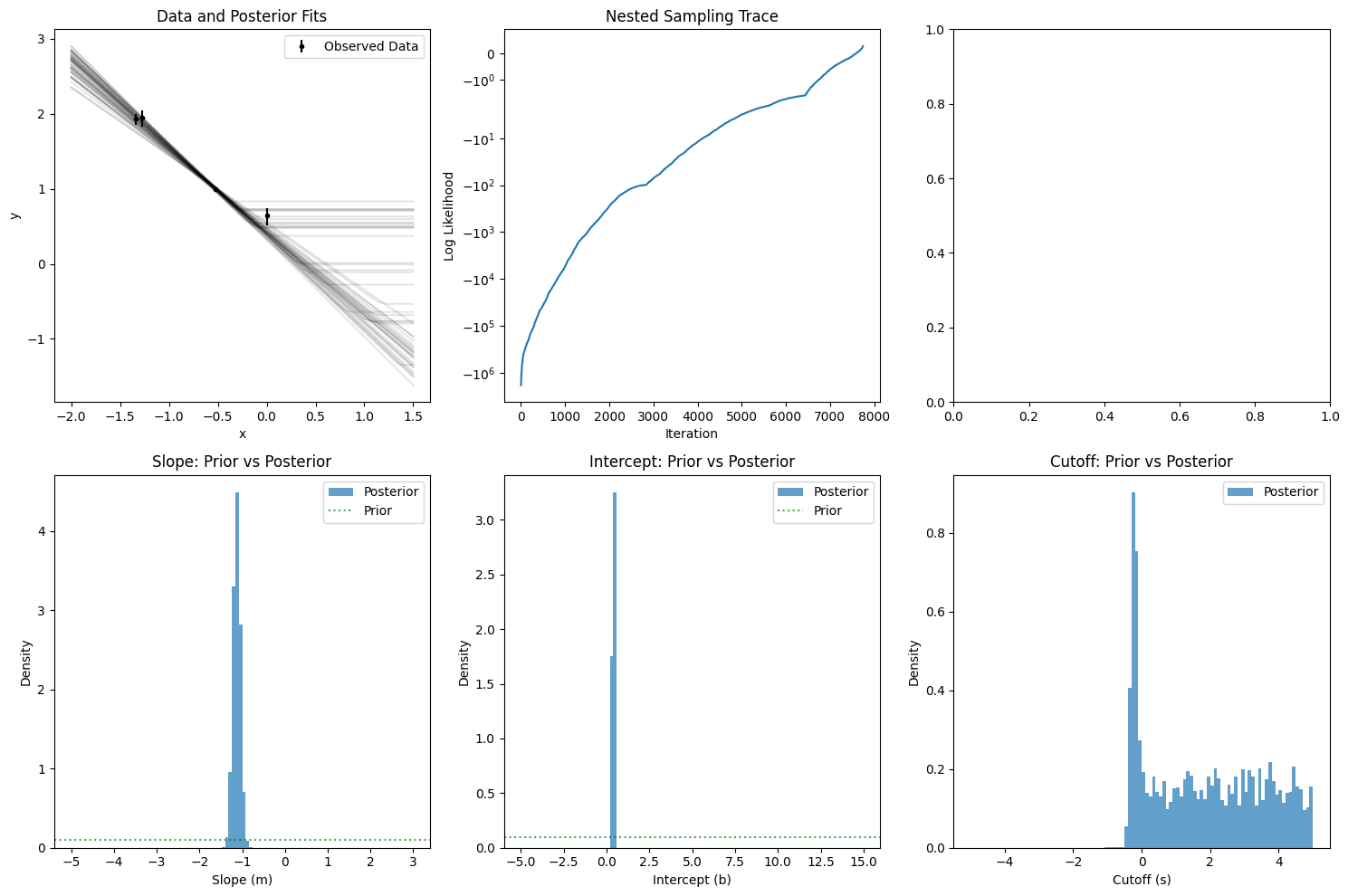
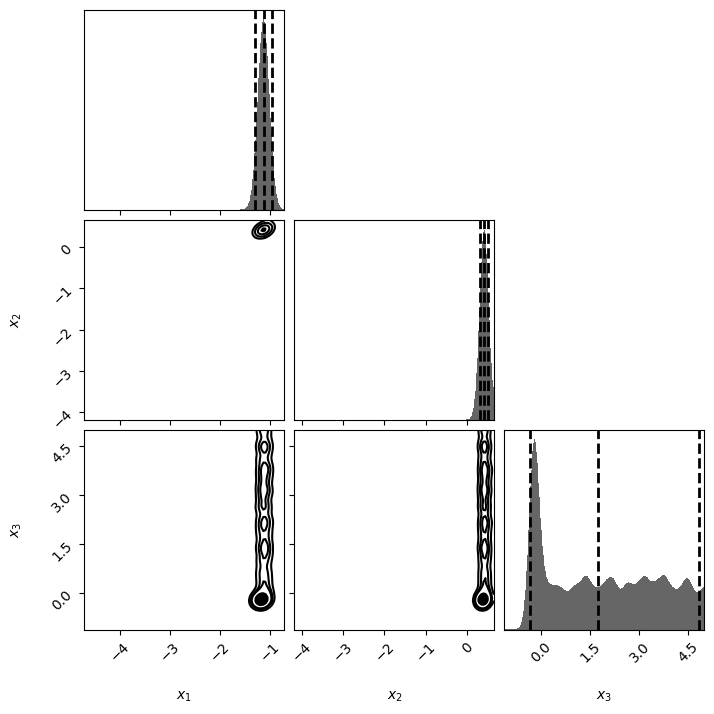
[58]:
from dynesty import utils as dyfunc
# Transit
samples_transit, weights_transit = results_transit.samples, results_transit.importance_weights()
mean_transit, cov_transit = dyfunc.mean_and_cov(samples_transit, weights_transit)
cov_transit = np.sqrt(np.diag(cov_transit))
# Emission
samples_emission, weights_emission = results_emission.samples, results_emission.importance_weights()
mean_emission, cov_emission = dyfunc.mean_and_cov(samples_emission, weights_emission)
cov_emission = np.sqrt(np.diag(cov_emission))
# Direct
samples_direct, weights_direct = results_direct.samples, results_direct.importance_weights()
mean_direct, cov_direct = dyfunc.mean_and_cov(samples_direct, weights_direct)
cov_direct = np.sqrt(np.diag(cov_direct))
# SS
samples_ss, weights_ss = results_ss.samples, results_ss.importance_weights()
mean_ss, cov_ss = dyfunc.mean_and_cov(samples_ss, weights_ss)
cov_ss = np.sqrt(np.diag(cov_ss))
# Transit (flat)
samples_transit_flat, weights_transit_flat = results_transit_flat.samples, results_transit_flat.importance_weights()
mean_transit_flat, cov_transit_flat = dyfunc.mean_and_cov(samples_transit_flat, weights_transit_flat)
cov_transit_flat = np.sqrt(np.diag(cov_transit_flat))
# Emission (flat)
samples_emission_flat, weights_emission_flat = results_emission_flat.samples, results_emission_flat.importance_weights()
mean_emission_flat, cov_emission_flat = dyfunc.mean_and_cov(samples_emission_flat, weights_emission_flat)
cov_emission_flat = np.sqrt(np.diag(cov_emission_flat))
# Direct (flat)
samples_direct_flat, weights_direct_flat = results_direct_flat.samples, results_direct_flat.importance_weights()
mean_direct_flat, cov_direct_flat = dyfunc.mean_and_cov(samples_direct_flat, weights_direct_flat)
cov_direct_flat = np.sqrt(np.diag(cov_direct_flat))
# SS (flat)
samples_ss_flat, weights_ss_flat = results_ss_flat.samples, results_ss_flat.importance_weights()
mean_ss_flat, cov_ss_flat = dyfunc.mean_and_cov(samples_ss_flat, weights_ss_flat)
cov_ss_flat = np.sqrt(np.diag(cov_ss_flat))
# Print LaTeX format
latex_string = f'''
Slope & ${mean_transit[0]:0.2f}\\pm{cov_transit[0]:0.2f}$ & ${mean_emission[0]:0.2f}\\pm{cov_emission[0]:0.2f}$ & ${mean_direct[0]:0.2f}\\pm{cov_direct[0]:0.2f}$ & ${mean_ss[0]:0.2f}\\pm{cov_ss[0]:0.2f}$ \\\\
Intercept (M/H) & ${mean_transit[1]:0.2f}\\pm{cov_transit[1]:0.2f}$ & ${mean_emission[1]:0.2f}\\pm{cov_emission[1]:0.2f}$ & ${mean_direct[1]:0.2f}\\pm{cov_direct[1]:0.2f}$ & ${mean_ss[1]:0.2f}\\pm{cov_ss[1]:0.2f}$ \\\\
Mass Cutoff (log10) & ${mean_transit[2]:0.2f}\\pm{cov_transit[2]:0.2f}$ & ${mean_emission[2]:0.2f}\\pm{cov_emission[2]:0.2f}$ & ${mean_direct[2]:0.2f}\\pm{cov_direct[2]:0.2f}$ & ${mean_ss[2]:0.2f}\\pm{cov_ss[2]:0.2f}$ \\\\
$\\ln E$ & ${np.max(results_transit.logz):0.2f} \\pm 0.2$ & ${np.max(results_emission.logz):0.2f} \\pm 0.2$ & ${np.max(results_direct.logz):0.2f} \\pm 0.2$ & ${np.max(results_ss.logz):0.2f} \\pm 0.2$ \\\\
\\hline \\
\\multicolumn{{4}}{{c}}{{\\textbf{{Flat-Line}}}} \\\\
\\textbf{{Parameter}} & \textbf{{Transiting}} & \\textbf{{Eclipse}} & \\textbf{{Direct}} & \\textbf{{Solar System}} \\\\
\\hline \\
Intercept (M/H) & ${mean_transit_flat[0]:0.2f}\\pm{cov_transit_flat[0]:0.2f}$ & ${mean_emission_flat[0]:0.2f}\\pm{cov_emission_flat[0]:0.2f}$ & ${mean_direct_flat[0]:0.2f}\\pm{cov_direct_flat[0]:0.2f}$ & ${mean_ss_flat[0]:0.2f}\\pm{cov_ss_flat[0]:0.2f}$ \\\\
$\\ln E$ & ${np.max(results_transit_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_emission_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_direct_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_ss_flat.logz):0.2f} \\pm 0.2$ \\\\
\\hline \\
'''
print(latex_string)
Slope & $-1.79\pm0.35$ & $-1.75\pm0.16$ & $-1.71\pm0.15$ & $-1.13\pm0.09$ \\
Intercept (M/H) & $-0.33\pm0.40$ & $0.29\pm0.04$ & $2.51\pm0.16$ & $0.41\pm0.07$ \\
Mass Cutoff (log10) & $-0.51\pm0.13$ & $0.22\pm0.02$ & $3.15\pm1.05$ & $1.84\pm1.70$ \\
$\ln E$ & $-123.40 \pm 0.2$ & $-157.11 \pm 0.2$ & $-146.34 \pm 0.2$ & $-11.88 \pm 0.2$ \\
\hline \
\multicolumn{4}{c}{\textbf{Flat-Line}} \\
\textbf{Parameter} & extbf{Transiting} & \textbf{Eclipse} & \textbf{Direct} & \textbf{Solar System} \\
\hline \
Intercept (M/H) & $0.93\pm0.04$ & $0.12\pm0.03$ & $0.71\pm0.03$ & $1.04\pm0.02$ \\
$\ln E$ & $-205.81 \pm 0.2$ & $-221.26 \pm 0.2$ & $-209.34 \pm 0.2$ & $-105.52 \pm 0.2$ \\
\hline \
O/H
[59]:
results_transit_flat = mass_mh_dynesty_flat(transit, plot_it=False, xerrs=False, oh=True)
results_emission_flat = mass_mh_dynesty_flat(emission, plot_it=False, xerrs=False, oh=True)
results_direct_flat = mass_mh_dynesty_flat(direct, plot_it=False, xerrs=False, oh=True)
results_ss_flat = mass_mh_dynesty_flat(solar_system, plot_it=False, xerrs=False, oh=True)
Running nested sampling...
3868it [00:02, 1918.49it/s, +500 | bound: 5 | nc: 1 | ncall: 22037 | eff(%): 20.281 | loglstar: -inf < -193.449 < inf | logz: -198.825 +/- 0.096 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -198.82 ± 0.12
Number of likelihood evaluations: 3868
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 9.673 [9.635, 9.713] [0.039, 0.040]
Running nested sampling...
3966it [00:01, 2007.03it/s, +500 | bound: 5 | nc: 1 | ncall: 22782 | eff(%): 20.043 | loglstar: -inf < -206.282 < inf | logz: -211.853 +/- 0.098 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -211.85 ± 0.13
Number of likelihood evaluations: 3966
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 8.816 [8.784, 8.851] [0.032, 0.035]
Running nested sampling...
3963it [00:01, 2045.17it/s, +500 | bound: 5 | nc: 1 | ncall: 21632 | eff(%): 21.120 | loglstar: -inf < -161.703 < inf | logz: -167.268 +/- 0.098 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -167.27 ± 0.12
Number of likelihood evaluations: 3963
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 9.374 [9.339, 9.405] [0.035, 0.031]
Running nested sampling...
4274it [00:01, 2157.30it/s, +500 | bound: 6 | nc: 1 | ncall: 22607 | eff(%): 21.595 | loglstar: -inf < -99.398 < inf | logz: -105.586 +/- 0.104 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -105.59 ± 0.13
Number of likelihood evaluations: 4274
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 9.732 [9.715, 9.747] [0.017, 0.015]
[60]:
results_transit = mass_mh_dynesty(transit, plot_it=False, xerrs=False, oh=True)
results_emission = mass_mh_dynesty(emission, plot_it=False, xerrs=False, oh=True)
results_direct = mass_mh_dynesty(direct, plot_it=False, xerrs=False, oh=True)
results_ss = mass_mh_dynesty(solar_system, plot_it=False, xerrs=False, oh=True)
Running nested sampling...
2423it [00:01, 789.34it/s, bound: 10 | nc: 71 | ncall: 24889 | eff(%): 9.735 | loglstar: -inf < -194.190 < inf | logz: -201.226 +/- 0.112 | dlogz: 90.702 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7098it [00:05, 1285.55it/s, +500 | bound: 38 | nc: 1 | ncall: 46204 | eff(%): 16.624 | loglstar: -inf < -104.892 < inf | logz: -116.733 +/- 0.146 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -116.73 ± 0.18
Number of likelihood evaluations: 7098
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.776 [-2.186, -1.458] [0.410, 0.318]
intercept (b) 8.429 [7.955, 8.787] [0.474, 0.358]
cutoff (s) -0.524 [-0.644, -0.385] [0.120, 0.139]
Running nested sampling...
2777it [00:04, 225.28it/s, bound: 32 | nc: 26 | ncall: 42114 | eff(%): 6.594 | loglstar: -inf < -206.620 < inf | logz: -213.633 +/- 0.112 | dlogz: 72.004 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2896it [00:06, 107.42it/s, bound: 47 | nc: 46 | ncall: 53583 | eff(%): 5.405 | loglstar: -inf < -206.287 < inf | logz: -212.881 +/- 0.110 | dlogz: 71.009 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2910it [00:07, 65.88it/s, bound: 52 | nc: 1048 | ncall: 57409 | eff(%): 5.069 | loglstar: -inf < -206.283 < inf | logz: -212.820 +/- 0.109 | dlogz: 70.921 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
8468it [00:10, 817.97it/s, +500 | bound: 77 | nc: 1 | ncall: 76016 | eff(%): 11.876 | loglstar: -inf < -131.416 < inf | logz: -146.002 +/- 0.162 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -146.00 ± 0.20
Number of likelihood evaluations: 8468
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.811 [-1.969, -1.658] [0.158, 0.153]
intercept (b) 8.961 [8.923, 9.000] [0.038, 0.039]
cutoff (s) 0.223 [0.211, 0.238] [0.011, 0.015]
Running nested sampling...
2773it [00:09, 37.19it/s, bound: 68 | nc: 585 | ncall: 67791 | eff(%): 4.091 | loglstar: -inf < -161.718 < inf | logz: -168.038 +/- 0.107 | dlogz: 46.872 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2800it [00:10, 40.28it/s, bound: 74 | nc: 184 | ncall: 72610 | eff(%): 3.856 | loglstar: -inf < -161.703 < inf | logz: -167.929 +/- 0.107 | dlogz: 46.708 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
6112it [00:12, 507.06it/s, +500 | bound: 90 | nc: 1 | ncall: 84637 | eff(%): 7.859 | loglstar: -inf < -115.351 < inf | logz: -125.231 +/- 0.132 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -125.23 ± 0.16
Number of likelihood evaluations: 6112
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.531 [-1.693, -1.360] [0.162, 0.171]
intercept (b) 10.994 [10.809, 11.172] [0.185, 0.177]
cutoff (s) 3.192 [1.895, 4.417] [1.298, 1.225]
Running nested sampling...
2737it [00:02, 635.84it/s, bound: 20 | nc: 38 | ncall: 33820 | eff(%): 8.093 | loglstar: -inf < -102.393 < inf | logz: -110.951 +/- 0.124 | dlogz: 103.887 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2884it [00:05, 251.94it/s, bound: 39 | nc: 992 | ncall: 48352 | eff(%): 5.965 | loglstar: -inf < -99.399 < inf | logz: -106.975 +/- 0.118 | dlogz: 99.585 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
4213it [00:07, 565.04it/s, bound: 55 | nc: 18 | ncall: 59774 | eff(%): 7.048 | loglstar: -inf < -9.267 < inf | logz: -19.498 +/- 0.137 | dlogz: 10.781 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
4397it [00:07, 338.74it/s, bound: 63 | nc: 39 | ncall: 66103 | eff(%): 6.652 | loglstar: -inf < -7.173 < inf | logz: -17.514 +/- 0.136 | dlogz: 8.428 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
4445it [00:08, 301.05it/s, bound: 65 | nc: 12 | ncall: 67753 | eff(%): 6.561 | loglstar: -inf < -6.672 < inf | logz: -17.079 +/- 0.136 | dlogz: 7.896 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7246it [00:10, 700.20it/s, +500 | bound: 85 | nc: 1 | ncall: 82710 | eff(%): 9.422 | loglstar: -inf < 0.294 < inf | logz: -11.858 +/- 0.144 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -11.86 ± 0.18
Number of likelihood evaluations: 7246
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.125 [-1.206, -1.049] [0.081, 0.076]
intercept (b) 9.101 [9.052, 9.147] [0.049, 0.046]
cutoff (s) 1.587 [-0.180, 3.848] [1.767, 2.261]
[62]:
from dynesty import utils as dyfunc
# Transit
samples_transit, weights_transit = results_transit.samples, results_transit.importance_weights()
mean_transit, cov_transit = dyfunc.mean_and_cov(samples_transit, weights_transit)
cov_transit = np.sqrt(np.diag(cov_transit))
# Emission
samples_emission, weights_emission = results_emission.samples, results_emission.importance_weights()
mean_emission, cov_emission = dyfunc.mean_and_cov(samples_emission, weights_emission)
cov_emission = np.sqrt(np.diag(cov_emission))
# Direct
samples_direct, weights_direct = results_direct.samples, results_direct.importance_weights()
mean_direct, cov_direct = dyfunc.mean_and_cov(samples_direct, weights_direct)
cov_direct = np.sqrt(np.diag(cov_direct))
# SS
samples_ss, weights_ss = results_ss.samples, results_ss.importance_weights()
mean_ss, cov_ss = dyfunc.mean_and_cov(samples_ss, weights_ss)
cov_ss = np.sqrt(np.diag(cov_ss))
# Transit (flat)
samples_transit_flat, weights_transit_flat = results_transit_flat.samples, results_transit_flat.importance_weights()
mean_transit_flat, cov_transit_flat = dyfunc.mean_and_cov(samples_transit_flat, weights_transit_flat)
cov_transit_flat = np.sqrt(np.diag(cov_transit_flat))
# Emission (flat)
samples_emission_flat, weights_emission_flat = results_emission_flat.samples, results_emission_flat.importance_weights()
mean_emission_flat, cov_emission_flat = dyfunc.mean_and_cov(samples_emission_flat, weights_emission_flat)
cov_emission_flat = np.sqrt(np.diag(cov_emission_flat))
# Direct (flat)
samples_direct_flat, weights_direct_flat = results_direct_flat.samples, results_direct_flat.importance_weights()
mean_direct_flat, cov_direct_flat = dyfunc.mean_and_cov(samples_direct_flat, weights_direct_flat)
cov_direct_flat = np.sqrt(np.diag(cov_direct_flat))
# SS (flat)
samples_ss_flat, weights_ss_flat = results_ss_flat.samples, results_ss_flat.importance_weights()
mean_ss_flat, cov_ss_flat = dyfunc.mean_and_cov(samples_ss_flat, weights_ss_flat)
cov_ss_flat = np.sqrt(np.diag(cov_ss_flat))
# Print LaTeX format
latex_string = f'''
Slope & ${mean_transit[0]:0.2f}\\pm{cov_transit[0]:0.2f}$ & ${mean_emission[0]:0.2f}\\pm{cov_emission[0]:0.2f}$ & ${mean_direct[0]:0.2f}\\pm{cov_direct[0]:0.2f}$ & ${mean_ss[0]:0.2f}\\pm{cov_ss[0]:0.2f}$ \\\\
Intercept (M/H) & ${mean_transit[1]:0.2f}\\pm{cov_transit[1]:0.2f}$ & ${mean_emission[1]:0.2f}\\pm{cov_emission[1]:0.2f}$ & ${mean_direct[1]:0.2f}\\pm{cov_direct[1]:0.2f}$ & ${mean_ss[1]:0.2f}\\pm{cov_ss[1]:0.2f}$ \\\\
Mass Cutoff (log10) & ${mean_transit[2]:0.2f}\\pm{cov_transit[2]:0.2f}$ & ${mean_emission[2]:0.2f}\\pm{cov_emission[2]:0.2f}$ & ${mean_direct[2]:0.2f}\\pm{cov_direct[2]:0.2f}$ & ${mean_ss[2]:0.2f}\\pm{cov_ss[2]:0.2f}$ \\\\
$\\ln E$ & ${np.max(results_transit.logz):0.2f} \\pm 0.2$ & ${np.max(results_emission.logz):0.2f} \\pm 0.2$ & ${np.max(results_direct.logz):0.2f} \\pm 0.2$ & ${np.max(results_ss.logz):0.2f} \\pm 0.2$ \\\\
\\hline \\
\\multicolumn{{5}}{{c}}{{\\textbf{{Flat-Line}}}} \\\\
\\textbf{{Parameter}} & \\textbf{{Transiting}} & \\textbf{{Eclipse}} & \\textbf{{Direct}} & \\textbf{{Solar System}} \\\\
\\hline \\
Intercept (M/H) & ${mean_transit_flat[0]:0.2f}\\pm{cov_transit_flat[0]:0.2f}$ & ${mean_emission_flat[0]:0.2f}\\pm{cov_emission_flat[0]:0.2f}$ & ${mean_direct_flat[0]:0.2f}\\pm{cov_direct_flat[0]:0.2f}$ & ${mean_ss_flat[0]:0.2f}\\pm{cov_ss_flat[0]:0.2f}$ \\\\
$\\ln E$ & ${np.max(results_transit_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_emission_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_direct_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_ss_flat.logz):0.2f} \\pm 0.2$ \\\\
\\hline \\
'''
print(latex_string)
Slope & $-1.81\pm0.35$ & $-1.81\pm0.16$ & $-1.53\pm0.16$ & $-1.13\pm0.09$ \\
Intercept (M/H) & $8.38\pm0.40$ & $8.96\pm0.04$ & $10.99\pm0.18$ & $9.10\pm0.07$ \\
Mass Cutoff (log10) & $-0.52\pm0.12$ & $0.22\pm0.02$ & $3.18\pm1.07$ & $1.77\pm1.70$ \\
$\ln E$ & $-116.73 \pm 0.2$ & $-146.00 \pm 0.2$ & $-125.23 \pm 0.2$ & $-11.86 \pm 0.2$ \\
\hline \
\multicolumn{5}{c}{\textbf{Flat-Line}} \\
\textbf{Parameter} & \textbf{Transiting} & \textbf{Eclipse} & \textbf{Direct} & \textbf{Solar System} \\
\hline \
Intercept (M/H) & $9.67\pm0.04$ & $8.82\pm0.03$ & $9.37\pm0.03$ & $9.73\pm0.02$ \\
$\ln E$ & $-198.82 \pm 0.2$ & $-211.85 \pm 0.2$ & $-167.27 \pm 0.2$ & $-105.59 \pm 0.2$ \\
\hline \
[63]:
fig, ax = plt.subplots(figsize=(9, 6))
#x = 10**(np.linspace(-2,2.0))
#fit = np.log10(9.7*(x**-0.45)) #[M/H] ~ log10(Z/Zs)
#ax.plot(x,fit,'k--',label='Thorgren+ 2016',zorder=1,alpha=0.75)
#plot w/o solar system for o/h
for data, result, label, marker, color in zip([direct, emission, transit],
[results_direct,results_emission,results_transit],
['Direct', 'Eclipse', 'Transmission'],
['o', 's', 'd'],
['#2E86AB', '#A23B72', '#F18F01']):
ax.errorbar(data['Mass'], data['O/H'],
xerr=[data['Mass Lower'], data['Mass Upper']],
yerr=[data['O/H Lower'], data['O/H Upper']],
fmt=marker, label=label, color=color,
markersize=6, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
n_samples = min(50, len(result['samples']))
indices = np.random.choice(len(result['samples']), n_samples, p=result.importance_weights()/np.sum(result.importance_weights()))
xfake = np.linspace(-2,2.5)
for idx in indices: # Plot subset for clarity
m_sample, b_sample, s_sample = result['samples'][idx, 0], result['samples'][idx, 1], result['samples'][idx, 2]
y_sample = m_sample * xfake + b_sample
y_sample[np.where(xfake > s_sample)[0]] = m_sample * s_sample + b_sample
ax.plot(10**xfake, y_sample, '-', alpha=0.05, color=color)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
ax.errorbar(row['Mass'], row['O/H'],
xerr=[[row['Mass Lower']], [row['Mass Upper']]],
yerr=[[row['O/H Lower']], [row['O/H Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
ax.set_xlim(0.025,50)
ax.set_xscale('log')
ax.set_ylim(7.5,12)
ax.set_xlabel(r'Mass [M$_{\mathrm{Jup}}$]', fontsize=16)
ax.set_ylabel('O/H', fontsize=16)
ax.legend(frameon=True, fancybox=True, shadow=False,fontsize=13)
ax.grid(True, alpha=0.3)
ax.minorticks_on()
ax.yaxis.set_ticks_position('both')
ax.xaxis.set_ticks_position('both')
plt.tight_layout()
ax.tick_params(labelsize=12)
#8.69
#9.7*M&-0.45
#ax.plot( np.logspace(-2,2), 8.69 + np.log10((9.7*np.logspace(-1,1)**-0.45)),'--k') #Thorngren, kinda - mass fraction
#plt.savefig('mass_metallicity_fits_oh.pdf')
X = 0.7381
Y = 0.2485
Z = 0.0134
ZM = (9.7*np.logspace(-2,2)**-0.45) * Z
ZH = (10**8.69+10**8.43+10**7.83) / 1e12
muZ = 18
muH = 2.0
factorZ = (1+(Y/X)) / (((1/ZM)-1)*(muZ/muH))
#C/M
CM = 10**8.69 / (1.04e-3*1e12)
MF = np.log10(factorZ*CM * 1e12)
#8.69
#9.7*M&-0.45
#ax.plot( np.logspace(-2,2), 8.69 + np.log10((9.7*np.logspace(-1,1)**-0.45)),'--k') #Thorngren, kinda - mass fraction
ax.plot(np.logspace(-2,2),MF,'--k',label='Thorngren+ 16 (Interior)')
ax.hlines(8.69,-2,100,'k',linestyle=':',label='Solar (Asplund+09)')
ax.legend(frameon=True, fancybox=True, shadow=False,fontsize=13)
plt.savefig('./paper_figs/mass_metallicity_fits_oh.pdf')
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/3002674758.py:73: RuntimeWarning: invalid value encountered in log10
MF = np.log10(factorZ*CM * 1e12)
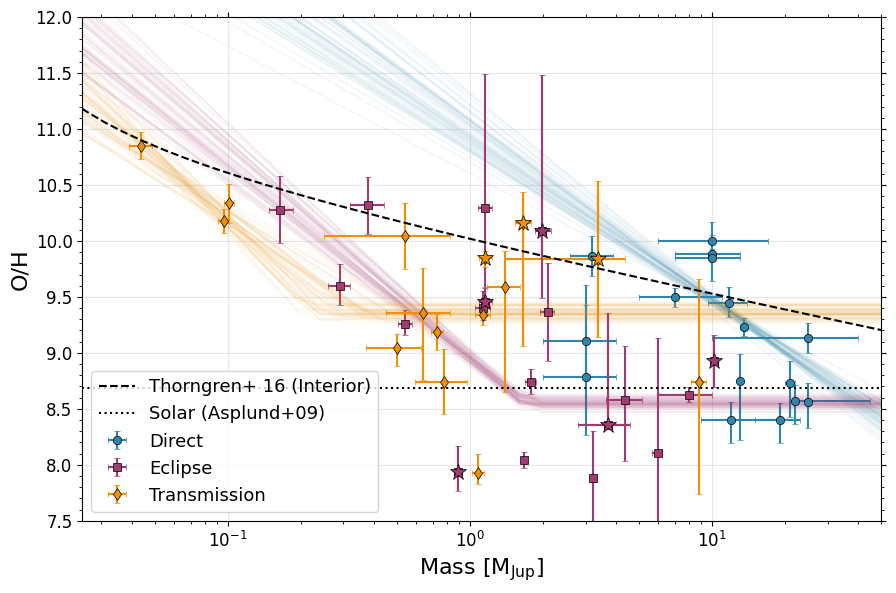
[64]:
params = ['Slope', 'Intercept', 'Cutoff']
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01','Solar System': '#808080'}
# Extract posterior samples
samples = results_transit['samples']
weights = results_transit.importance_weights()
lw = 2
fig,ax = plt.subplots(1,3,figsize=(15,6))
ax[0].hist(results_transit['samples'][:, 0],weights = results_transit.importance_weights(),density=True,bins=100,label='Transit',
ec=color_map['Transit'],fc=color_map['Transit'] + '60',histtype='stepfilled',linewidth=lw)
ax[0].hist(results_emission['samples'][:, 0],weights = results_emission.importance_weights(),density=True,bins=100,label='Eclipse',
ec=color_map['Eclipse'],fc=color_map['Eclipse'] + '60',histtype='stepfilled',linewidth=lw)
ax[0].hist(results_direct['samples'][:, 0],weights = results_direct.importance_weights(),density=True,bins=100,label='Direct',
ec=color_map['Direct'],fc=color_map['Direct'] + '60',histtype='stepfilled',linewidth=lw)
#ax[0].hist(results_ss['samples'][:, 0],weights = results_ss.importance_weights(),density=True,bins=100,label='Solar System',
# ec=color_map['Solar System'],fc=color_map['Solar System'] + '60',histtype='stepfilled',linewidth=lw)
#ax[0].set_title(f'{params[0]}')
ax[0].set_xlim(-3.5,-0.5)
ax[0].set_ylabel('Frequency',fontsize=16)
ax[0].set_xlabel(f'{params[0]}',fontsize=16)
ax[0].tick_params(labelsize=12)
ax[1].hist(results_transit['samples'][:, 1],weights = results_transit.importance_weights(),density=True,bins=100,label='Transit',
ec=color_map['Transit'],fc=color_map['Transit'] + '60',histtype='stepfilled',linewidth=lw)
ax[1].hist(results_emission['samples'][:, 1],weights = results_emission.importance_weights(),density=True,bins=100,label='Eclipse',
ec=color_map['Eclipse'],fc=color_map['Eclipse'] + '60',histtype='stepfilled',linewidth=lw)
ax[1].hist(results_direct['samples'][:, 1],weights = results_direct.importance_weights(),density=True,bins=100,label='Direct',
ec=color_map['Direct'],fc=color_map['Direct'] + '60',histtype='stepfilled',linewidth=lw)
#ax[1].hist(results_ss['samples'][:, 1],weights = results_ss.importance_weights(),density=True,bins=100,label='Solar System',
# ec=color_map['Solar System'],fc=color_map['Solar System'] + '60',histtype='stepfilled',linewidth=lw)
#ax[1].set_title(f'{params[1]}')
ax[1].set_xlim(7,12.5)
ax[1].set_xlabel(f'{params[1]}',fontsize=16)
ax[1].tick_params(labelsize=12)
ax[2].hist(results_transit['samples'][:, 2],weights = results_transit.importance_weights(),density=True,bins=100,label='Transit',
ec=color_map['Transit'],fc=color_map['Transit'] + '60',histtype='stepfilled',linewidth=lw)
ax[2].hist(results_emission['samples'][:, 2],weights = results_emission.importance_weights(),density=True,bins=100,label='Eclipse',
ec=color_map['Eclipse'],fc=color_map['Eclipse'] + '60',histtype='stepfilled',linewidth=lw)
ax[2].hist(results_direct['samples'][:, 2],weights = results_direct.importance_weights(),density=True,bins=100,label='Direct',
ec=color_map['Direct'],fc=color_map['Direct'] + '60',histtype='stepfilled',linewidth=lw)
#ax[2].hist(results_ss['samples'][:, 2],weights = results_ss.importance_weights(),density=True,bins=100,label='Solar System',
# ec=color_map['Solar System'],fc=color_map['Solar System'] + '60',histtype='stepfilled',linewidth=lw)
#ax[2].set_title(f'{params[2]}')
ax[2].set_xlim(-1,2)
ax[2].set_xlabel(f'{params[2]}',fontsize=16)
ax[2].tick_params(labelsize=12)
ax[2].legend(fontsize=13)
ax[0].minorticks_on()
ax[1].minorticks_on()
ax[2].minorticks_on()
ax[0].yaxis.set_ticks_position('both')
ax[0].xaxis.set_ticks_position('both')
ax[1].yaxis.set_ticks_position('both')
ax[1].xaxis.set_ticks_position('both')
ax[2].yaxis.set_ticks_position('both')
ax[2].xaxis.set_ticks_position('both')
plt.tight_layout()
#ax.tick_params(labelsize=12)
plt.savefig('./paper_figs/mass_metallicity_posteriors_oh.pdf')
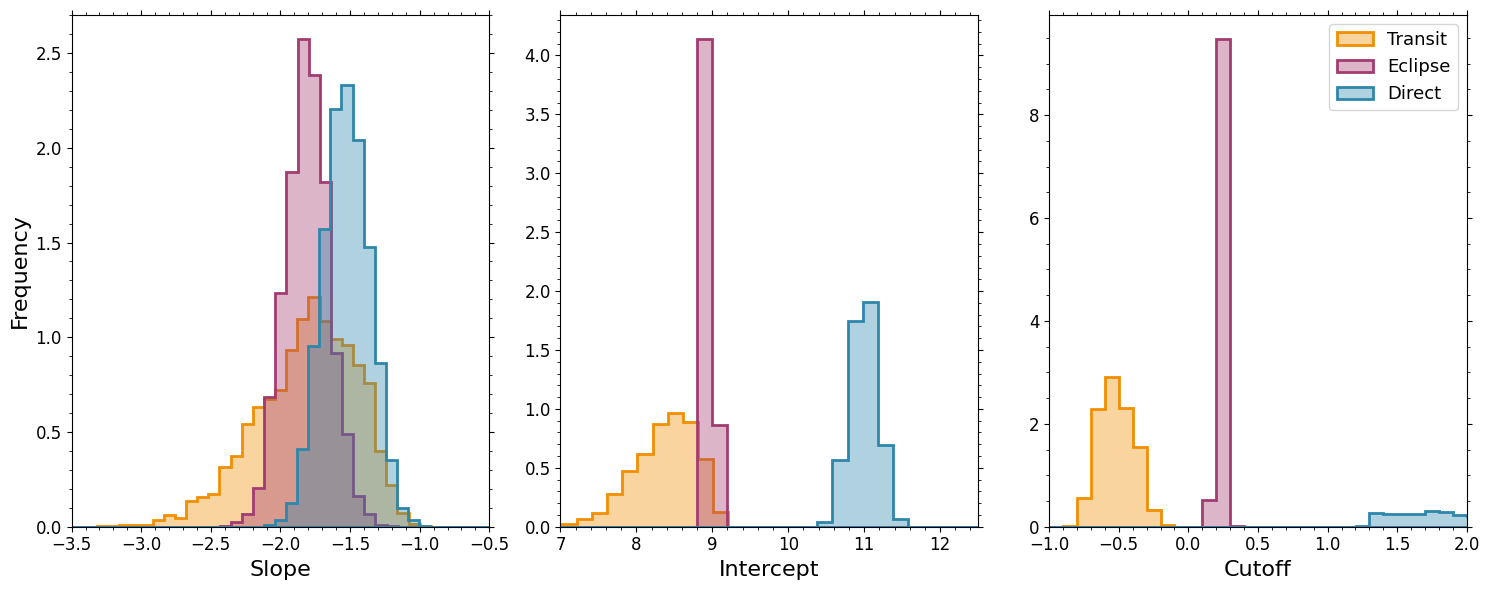
C/H
[65]:
results_transit_flat = mass_mh_dynesty_flat(transit, plot_it=False, xerrs=False, ch=True)
results_emission_flat = mass_mh_dynesty_flat(emission, plot_it=False, xerrs=False, ch=True)
results_direct_flat = mass_mh_dynesty_flat(direct, plot_it=False, xerrs=False, ch=True)
results_ss_flat = mass_mh_dynesty_flat(solar_system, plot_it=False, xerrs=False,ch=True)
Running nested sampling...
3764it [00:01, 1941.57it/s, +500 | bound: 5 | nc: 1 | ncall: 20887 | eff(%): 20.915 | loglstar: -inf < -175.093 < inf | logz: -180.261 +/- 0.094 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -180.26 ± 0.12
Number of likelihood evaluations: 3764
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 9.395 [9.355, 9.435] [0.040, 0.040]
Running nested sampling...
3892it [00:02, 1838.08it/s, +500 | bound: 5 | nc: 1 | ncall: 21241 | eff(%): 21.175 | loglstar: -inf < -219.076 < inf | logz: -224.500 +/- 0.097 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -224.50 ± 0.12
Number of likelihood evaluations: 3892
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 8.518 [8.485, 8.548] [0.033, 0.030]
Running nested sampling...
3977it [00:02, 1931.50it/s, +500 | bound: 5 | nc: 1 | ncall: 22033 | eff(%): 20.791 | loglstar: -inf < -202.967 < inf | logz: -208.560 +/- 0.098 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -208.56 ± 0.13
Number of likelihood evaluations: 3977
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 9.144 [9.114, 9.172] [0.030, 0.029]
Running nested sampling...
4189it [00:01, 2104.86it/s, +500 | bound: 6 | nc: 1 | ncall: 22249 | eff(%): 21.560 | loglstar: -inf < -99.398 < inf | logz: -105.416 +/- 0.103 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -105.42 ± 0.13
Number of likelihood evaluations: 4189
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) 9.470 [9.455, 9.486] [0.016, 0.016]
[66]:
results_transit = mass_mh_dynesty(transit, plot_it=False, xerrs=False, ch=True)
results_emission = mass_mh_dynesty(emission, plot_it=False, xerrs=False, ch=True)
results_direct = mass_mh_dynesty(direct, plot_it=False, xerrs=False, ch=True)
results_ss = mass_mh_dynesty(solar_system, plot_it=False, xerrs=False,ch=True)
Running nested sampling...
2539it [00:02, 671.05it/s, bound: 13 | nc: 17 | ncall: 27712 | eff(%): 9.162 | loglstar: -inf < -176.167 < inf | logz: -183.361 +/- 0.113 | dlogz: 61.472 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2651it [00:03, 329.54it/s, bound: 23 | nc: 17 | ncall: 35137 | eff(%): 7.545 | loglstar: -inf < -175.162 < inf | logz: -181.914 +/- 0.110 | dlogz: 61.022 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7044it [00:06, 1010.35it/s, +500 | bound: 51 | nc: 1 | ncall: 56357 | eff(%): 13.506 | loglstar: -inf < -115.278 < inf | logz: -127.012 +/- 0.145 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -127.01 ± 0.18
Number of likelihood evaluations: 7044
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.639 [-2.061, -1.277] [0.422, 0.362]
intercept (b) 8.153 [7.656, 8.568] [0.497, 0.415]
cutoff (s) -0.598 [-0.717, -0.433] [0.120, 0.165]
Running nested sampling...
2807it [00:05, 121.94it/s, bound: 41 | nc: 128 | ncall: 47905 | eff(%): 5.860 | loglstar: -inf < -219.108 < inf | logz: -225.789 +/- 0.110 | dlogz: 68.809 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2837it [00:06, 79.83it/s, bound: 47 | nc: 53 | ncall: 52595 | eff(%): 5.394 | loglstar: -inf < -219.079 < inf | logz: -225.630 +/- 0.110 | dlogz: 68.589 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7999it [00:10, 759.72it/s, +500 | bound: 78 | nc: 1 | ncall: 75748 | eff(%): 11.295 | loglstar: -inf < -148.332 < inf | logz: -161.996 +/- 0.154 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -162.00 ± 0.19
Number of likelihood evaluations: 7999
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.721 [-1.927, -1.519] [0.206, 0.202]
intercept (b) 8.742 [8.695, 8.786] [0.047, 0.045]
cutoff (s) 0.313 [0.221, 0.388] [0.092, 0.075]
Running nested sampling...
2478it [00:03, 402.70it/s, bound: 21 | nc: 19 | ncall: 33339 | eff(%): 7.433 | loglstar: -inf < -204.039 < inf | logz: -211.231 +/- 0.112 | dlogz: 69.485 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2572it [00:05, 188.70it/s, bound: 37 | nc: 132 | ncall: 45844 | eff(%): 5.610 | loglstar: -inf < -203.241 < inf | logz: -209.950 +/- 0.110 | dlogz: 68.007 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2637it [00:09, 85.19it/s, bound: 66 | nc: 118 | ncall: 67130 | eff(%): 3.928 | loglstar: -inf < -203.006 < inf | logz: -209.433 +/- 0.108 | dlogz: 67.357 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
6031it [00:12, 486.81it/s, +500 | bound: 90 | nc: 1 | ncall: 85654 | eff(%): 7.670 | loglstar: -inf < -136.648 < inf | logz: -146.350 +/- 0.132 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -146.35 ± 0.16
Number of likelihood evaluations: 6031
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.702 [-1.854, -1.559] [0.153, 0.143]
intercept (b) 10.943 [10.785, 11.104] [0.158, 0.160]
cutoff (s) 3.211 [1.932, 4.409] [1.279, 1.198]
Running nested sampling...
2486it [00:02, 858.77it/s, bound: 14 | nc: 17 | ncall: 27479 | eff(%): 9.047 | loglstar: -inf < -107.551 < inf | logz: -116.390 +/- 0.125 | dlogz: 109.319 > 0.100]/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
2688it [00:04, 332.34it/s, bound: 33 | nc: 33 | ncall: 41775 | eff(%): 6.434 | loglstar: -inf < -99.744 < inf | logz: -107.445 +/- 0.118 | dlogz: 100.483 > 0.100] /Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
/Users/jlothringer/miniconda3/envs/research/lib/python3.12/site-packages/dynesty/bounding.py:617: UserWarning: The enlargement factor for the ellipsoidal bounds determined from bootstrapping is very large. If you are using uniform sampling that may mean that the sampling will be inefficient. This may be caused by a very complex posterior shape. You may consider using more livepoints or different sampler (i.e. rslice or rwalk) or alternatively disable bootstrap (bootstrap=0)
warnings.warn(
7136it [00:09, 777.33it/s, +500 | bound: 73 | nc: 1 | ncall: 71983 | eff(%): 10.682 | loglstar: -inf < 0.308 < inf | logz: -11.628 +/- 0.142 | dlogz: 0.000 > 0.100]
Nested Sampling Results:
Log Evidence: -11.63 ± 0.17
Number of likelihood evaluations: 7136
Parameter Estimates:
Parameter Median 68% CI - / +
---------------------------------------------
slope (m) -1.128 [-1.210, -1.042] [0.082, 0.086]
intercept (b) 8.840 [8.791, 8.893] [0.050, 0.052]
cutoff (s) 1.725 [-0.180, 3.973] [1.905, 2.248]
[67]:
from dynesty import utils as dyfunc
# Transit
samples_transit, weights_transit = results_transit.samples, results_transit.importance_weights()
mean_transit, cov_transit = dyfunc.mean_and_cov(samples_transit, weights_transit)
cov_transit = np.sqrt(np.diag(cov_transit))
# Emission
samples_emission, weights_emission = results_emission.samples, results_emission.importance_weights()
mean_emission, cov_emission = dyfunc.mean_and_cov(samples_emission, weights_emission)
cov_emission = np.sqrt(np.diag(cov_emission))
# Direct
samples_direct, weights_direct = results_direct.samples, results_direct.importance_weights()
mean_direct, cov_direct = dyfunc.mean_and_cov(samples_direct, weights_direct)
cov_direct = np.sqrt(np.diag(cov_direct))
# SS
samples_ss, weights_ss = results_ss.samples, results_ss.importance_weights()
mean_ss, cov_ss = dyfunc.mean_and_cov(samples_ss, weights_ss)
cov_ss = np.sqrt(np.diag(cov_ss))
# Transit (flat)
samples_transit_flat, weights_transit_flat = results_transit_flat.samples, results_transit_flat.importance_weights()
mean_transit_flat, cov_transit_flat = dyfunc.mean_and_cov(samples_transit_flat, weights_transit_flat)
cov_transit_flat = np.sqrt(np.diag(cov_transit_flat))
# Emission (flat)
samples_emission_flat, weights_emission_flat = results_emission_flat.samples, results_emission_flat.importance_weights()
mean_emission_flat, cov_emission_flat = dyfunc.mean_and_cov(samples_emission_flat, weights_emission_flat)
cov_emission_flat = np.sqrt(np.diag(cov_emission_flat))
# Direct (flat)
samples_direct_flat, weights_direct_flat = results_direct_flat.samples, results_direct_flat.importance_weights()
mean_direct_flat, cov_direct_flat = dyfunc.mean_and_cov(samples_direct_flat, weights_direct_flat)
cov_direct_flat = np.sqrt(np.diag(cov_direct_flat))
# SS (flat)
samples_ss_flat, weights_ss_flat = results_ss_flat.samples, results_ss_flat.importance_weights()
mean_ss_flat, cov_ss_flat = dyfunc.mean_and_cov(samples_ss_flat, weights_ss_flat)
cov_ss_flat = np.sqrt(np.diag(cov_ss_flat))
# Print LaTeX format
latex_string = f'''
Slope & ${mean_transit[0]:0.2f}\\pm{cov_transit[0]:0.2f}$ & ${mean_emission[0]:0.2f}\\pm{cov_emission[0]:0.2f}$ & ${mean_direct[0]:0.2f}\\pm{cov_direct[0]:0.2f}$ & ${mean_ss[0]:0.2f}\\pm{cov_ss[0]:0.2f}$ \\\\
Intercept (M/H) & ${mean_transit[1]:0.2f}\\pm{cov_transit[1]:0.2f}$ & ${mean_emission[1]:0.2f}\\pm{cov_emission[1]:0.2f}$ & ${mean_direct[1]:0.2f}\\pm{cov_direct[1]:0.2f}$ & ${mean_ss[1]:0.2f}\\pm{cov_ss[1]:0.2f}$ \\\\
Mass Cutoff (log10) & ${mean_transit[2]:0.2f}\\pm{cov_transit[2]:0.2f}$ & ${mean_emission[2]:0.2f}\\pm{cov_emission[2]:0.2f}$ & ${mean_direct[2]:0.2f}\\pm{cov_direct[2]:0.2f}$ & ${mean_ss[2]:0.2f}\\pm{cov_ss[2]:0.2f}$ \\\\
$\\ln E$ & ${np.max(results_transit.logz):0.2f} \\pm 0.2$ & ${np.max(results_emission.logz):0.2f} \\pm 0.2$ & ${np.max(results_direct.logz):0.2f} \\pm 0.2$ & ${np.max(results_ss.logz):0.2f} \\pm 0.2$ \\\\
\\hline \\
\\multicolumn{{5}}{{c}}{{\\textbf{{Flat-Line}}}} \\\\
\\textbf{{Parameter}} & \\textbf{{Transiting}} & \\textbf{{Eclipse}} & \\textbf{{Direct}} & \\textbf{{Solar System}} \\\\
\\hline \\
Intercept (M/H) & ${mean_transit_flat[0]:0.2f}\\pm{cov_transit_flat[0]:0.2f}$ & ${mean_emission_flat[0]:0.2f}\\pm{cov_emission_flat[0]:0.2f}$ & ${mean_direct_flat[0]:0.2f}\\pm{cov_direct_flat[0]:0.2f}$ & ${mean_ss_flat[0]:0.2f}\\pm{cov_ss_flat[0]:0.2f}$ \\\\
$\\ln E$ & ${np.max(results_transit_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_emission_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_direct_flat.logz):0.2f} \\pm 0.2$ & ${np.max(results_ss_flat.logz):0.2f} \\pm 0.2$ \\\\
\\hline \\
'''
print(latex_string)
Slope & $-1.67\pm0.38$ & $-1.72\pm0.20$ & $-1.70\pm0.15$ & $-1.13\pm0.09$ \\
Intercept (M/H) & $8.11\pm0.43$ & $8.74\pm0.04$ & $10.94\pm0.16$ & $8.84\pm0.07$ \\
Mass Cutoff (log10) & $-0.58\pm0.13$ & $0.31\pm0.08$ & $3.19\pm1.06$ & $1.83\pm1.73$ \\
$\ln E$ & $-127.01 \pm 0.2$ & $-162.00 \pm 0.2$ & $-146.35 \pm 0.2$ & $-11.63 \pm 0.2$ \\
\hline \
\multicolumn{5}{c}{\textbf{Flat-Line}} \\
\textbf{Parameter} & \textbf{Transiting} & \textbf{Eclipse} & \textbf{Direct} & \textbf{Solar System} \\
\hline \
Intercept (M/H) & $9.39\pm0.04$ & $8.52\pm0.03$ & $9.14\pm0.03$ & $9.47\pm0.02$ \\
$\ln E$ & $-180.26 \pm 0.2$ & $-224.50 \pm 0.2$ & $-208.56 \pm 0.2$ & $-105.42 \pm 0.2$ \\
\hline \
[49]:
fig, ax = plt.subplots(figsize=(9, 6))
#x = 10**(np.linspace(-2,2.0))
#fit = np.log10(9.7*(x**-0.45)) #[M/H] ~ log10(Z/Zs)
#ax.plot(x,fit,'k--',label='Thorgren+ 2016',zorder=1,alpha=0.75)
for data, result, label, marker, color in zip([direct, emission, transit,solar_system],
[results_direct,results_emission,results_transit,results_ss],
['Direct', 'Eclipse', 'Transmission','Solar System'],
['o', 's', 'd', 'H'],
['#2E86AB', '#A23B72', '#F18F01', '#808080']):
ax.errorbar(data['Mass'], data['C/H'],
xerr=[data['Mass Lower'], data['Mass Upper']],
yerr=[data['C/H Lower'], data['C/H Upper']],
fmt=marker, label=label, color=color,
markersize=6, capsize=2, alpha=1.0,
markeredgecolor='k',markeredgewidth=0.5)
n_samples = min(50, len(result['samples']))
indices = np.random.choice(len(result['samples']), n_samples, p=result.importance_weights()/np.sum(result.importance_weights()))
xfake = np.linspace(-2,2.5)
for idx in indices: # Plot subset for clarity
m_sample, b_sample, s_sample = result['samples'][idx, 0], result['samples'][idx, 1], result['samples'][idx, 2]
y_sample = m_sample * xfake + b_sample
y_sample[np.where(xfake > s_sample)[0]] = m_sample * s_sample + b_sample
ax.plot(10**xfake, y_sample, '-', alpha=0.05, color=color)
for _, row in uhjs.iterrows():
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01'}
ax.errorbar(row['Mass'], row['C/H'],
xerr=[[row['Mass Lower']], [row['Mass Upper']]],
yerr=[[row['C/H Lower']], [row['C/H Upper']]],
fmt='*', color=color_map[row['Geometry']], markersize=12,
markeredgecolor='k',markeredgewidth=0.5)
ax.set_xlim(0.025,50)
ax.set_xscale('log')
ax.set_ylim(7.0,11.5)
ax.set_xlabel(r'Mass [M$_{\mathrm{Jup}}$]', fontsize=16)
ax.set_ylabel('C/H', fontsize=16)
ax.legend(frameon=True, fancybox=True, shadow=False,fontsize=13)
ax.grid(True, alpha=0.3)
ax.minorticks_on()
ax.yaxis.set_ticks_position('both')
ax.xaxis.set_ticks_position('both')
plt.tight_layout()
ax.tick_params(labelsize=12)
X = 0.7381
Y = 0.2485
Z = 0.0134
ZM = (9.7*np.logspace(-2,2)**-0.45) * Z
ZH = (10**8.69+10**8.43+10**7.83) / 1e12
muZ = 18
muH = 2.0
factorZ = (1+(Y/X)) / (((1/ZM)-1)*(muZ/muH))
#C/M
CM = 10**8.43 / (1.04e-3*1e12)
MF = np.log10(factorZ*CM * 1e12)
#8.69
#9.7*M&-0.45
#ax.plot( np.logspace(-2,2), 8.69 + np.log10((9.7*np.logspace(-1,1)**-0.45)),'--k') #Thorngren, kinda - mass fraction
ax.plot(np.logspace(-2,2),MF,'--k',label='Thorngren+ 16 (Interior)')
#yayaati's paper
a = 2.6
b = 3.3
ZM2 = (a/np.logspace(-2,2) + b) * Z
factorZ2 = (1+(Y/X)) / (((1/ZM2)-1)*(muZ/muH))
MF2 = np.log10(factorZ2*CM * 1e12)
#ax.plot(np.logspace(-2,2),MF2,'-.k',label='Chachan+ 25 (Interior)')
ax.hlines(8.43,-2,100,'k',linestyle=':',label='Asplund+09/21 Solar')
ax.legend(frameon=True, fancybox=True, shadow=False,fontsize=13,framealpha=1.0)
plt.savefig('./paper_figs/mass_metallicity_fits_ch.pdf')
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2982232166.py:68: RuntimeWarning: invalid value encountered in log10
MF = np.log10(factorZ*CM * 1e12)
/var/folders/mv/w837twcj1x15d56059x6tb640005r5/T/ipykernel_20318/2982232166.py:80: RuntimeWarning: invalid value encountered in log10
MF2 = np.log10(factorZ2*CM * 1e12)
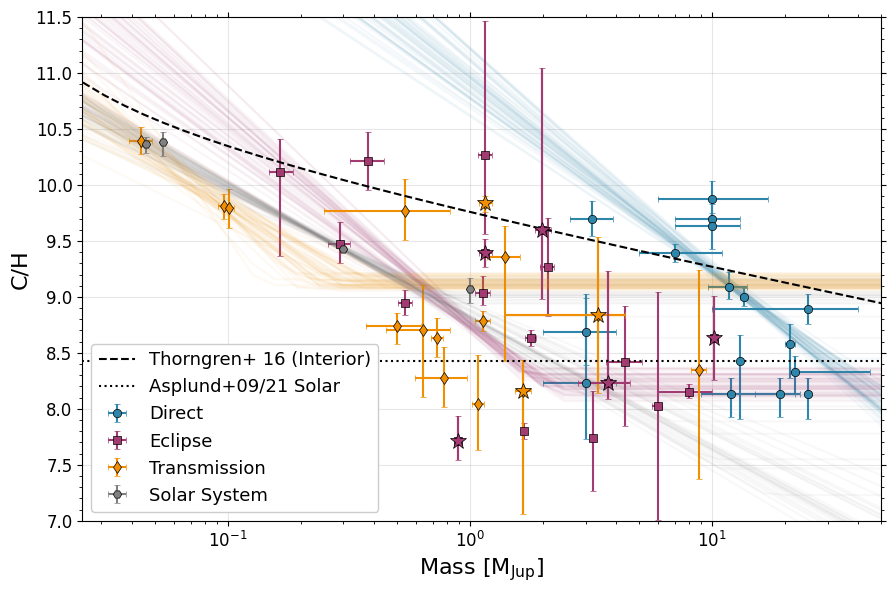
[50]:
params = ['Slope', 'Intercept', 'Cutoff']
color_map = {'Direct': '#2E86AB', 'Eclipse': '#A23B72', 'Transit': '#F18F01','Solar System': '#808080'}
# Extract posterior samples
samples = results_transit['samples']
weights = results_transit.importance_weights()
lw = 2
fig,ax = plt.subplots(1,3,figsize=(15,6))
ax[0].hist(results_transit['samples'][:, 0],weights = results_transit.importance_weights(),density=True,bins=100,label='Transit',
ec=color_map['Transit'],fc=color_map['Transit'] + '60',histtype='stepfilled',linewidth=lw)
ax[0].hist(results_emission['samples'][:, 0],weights = results_emission.importance_weights(),density=True,bins=100,label='Eclipse',
ec=color_map['Eclipse'],fc=color_map['Eclipse'] + '60',histtype='stepfilled',linewidth=lw)
ax[0].hist(results_direct['samples'][:, 0],weights = results_direct.importance_weights(),density=True,bins=100,label='Direct',
ec=color_map['Direct'],fc=color_map['Direct'] + '60',histtype='stepfilled',linewidth=lw)
ax[0].hist(results_ss['samples'][:, 0],weights = results_ss.importance_weights(),density=True,bins=100,label='Solar System',
ec=color_map['Solar System'],fc=color_map['Solar System'] + '60',histtype='stepfilled',linewidth=lw)
#ax[0].set_title(f'{params[0]}')
ax[0].set_xlim(-3.5,-0.5)
ax[0].set_ylabel('Frequency',fontsize=16)
ax[0].set_xlabel(f'{params[0]}',fontsize=16)
ax[0].tick_params(labelsize=12)
ax[1].hist(results_transit['samples'][:, 1],weights = results_transit.importance_weights(),density=True,bins=100,label='Transit',
ec=color_map['Transit'],fc=color_map['Transit'] + '60',histtype='stepfilled',linewidth=lw)
ax[1].hist(results_emission['samples'][:, 1],weights = results_emission.importance_weights(),density=True,bins=100,label='Eclipse',
ec=color_map['Eclipse'],fc=color_map['Eclipse'] + '60',histtype='stepfilled',linewidth=lw)
ax[1].hist(results_direct['samples'][:, 1],weights = results_direct.importance_weights(),density=True,bins=100,label='Direct',
ec=color_map['Direct'],fc=color_map['Direct'] + '60',histtype='stepfilled',linewidth=lw)
ax[1].hist(results_ss['samples'][:, 1],weights = results_ss.importance_weights(),density=True,bins=100,label='Solar System',
ec=color_map['Solar System'],fc=color_map['Solar System'] + '60',histtype='stepfilled',linewidth=lw)
#ax[1].set_title(f'{params[1]}')
ax[1].set_xlim(7,12.5)
ax[1].set_xlabel(f'{params[1]}',fontsize=16)
ax[1].tick_params(labelsize=12)
ax[2].hist(results_transit['samples'][:, 2],weights = results_transit.importance_weights(),density=True,bins=100,label='Transit',
ec=color_map['Transit'],fc=color_map['Transit'] + '60',histtype='stepfilled',linewidth=lw)
ax[2].hist(results_emission['samples'][:, 2],weights = results_emission.importance_weights(),density=True,bins=100,label='Eclipse',
ec=color_map['Eclipse'],fc=color_map['Eclipse'] + '60',histtype='stepfilled',linewidth=lw)
ax[2].hist(results_direct['samples'][:, 2],weights = results_direct.importance_weights(),density=True,bins=100,label='Direct',
ec=color_map['Direct'],fc=color_map['Direct'] + '60',histtype='stepfilled',linewidth=lw)
ax[2].hist(results_ss['samples'][:, 2],weights = results_ss.importance_weights(),density=True,bins=100,label='Solar System',
ec=color_map['Solar System'],fc=color_map['Solar System'] + '60',histtype='stepfilled',linewidth=lw)
#ax[2].set_title(f'{params[2]}')
ax[2].set_xlim(-1,2.0)
ax[2].set_xlabel(f'{params[2]}',fontsize=16)
ax[2].tick_params(labelsize=12)
ax[2].legend(fontsize=13)
ax[0].minorticks_on()
ax[1].minorticks_on()
ax[2].minorticks_on()
ax[0].yaxis.set_ticks_position('both')
ax[0].xaxis.set_ticks_position('both')
ax[1].yaxis.set_ticks_position('both')
ax[1].xaxis.set_ticks_position('both')
ax[2].yaxis.set_ticks_position('both')
ax[2].xaxis.set_ticks_position('both')
plt.tight_layout()
#ax.tick_params(labelsize=12)
plt.savefig('./paper_figs/mass_metallicity_posteriors_ch.pdf')
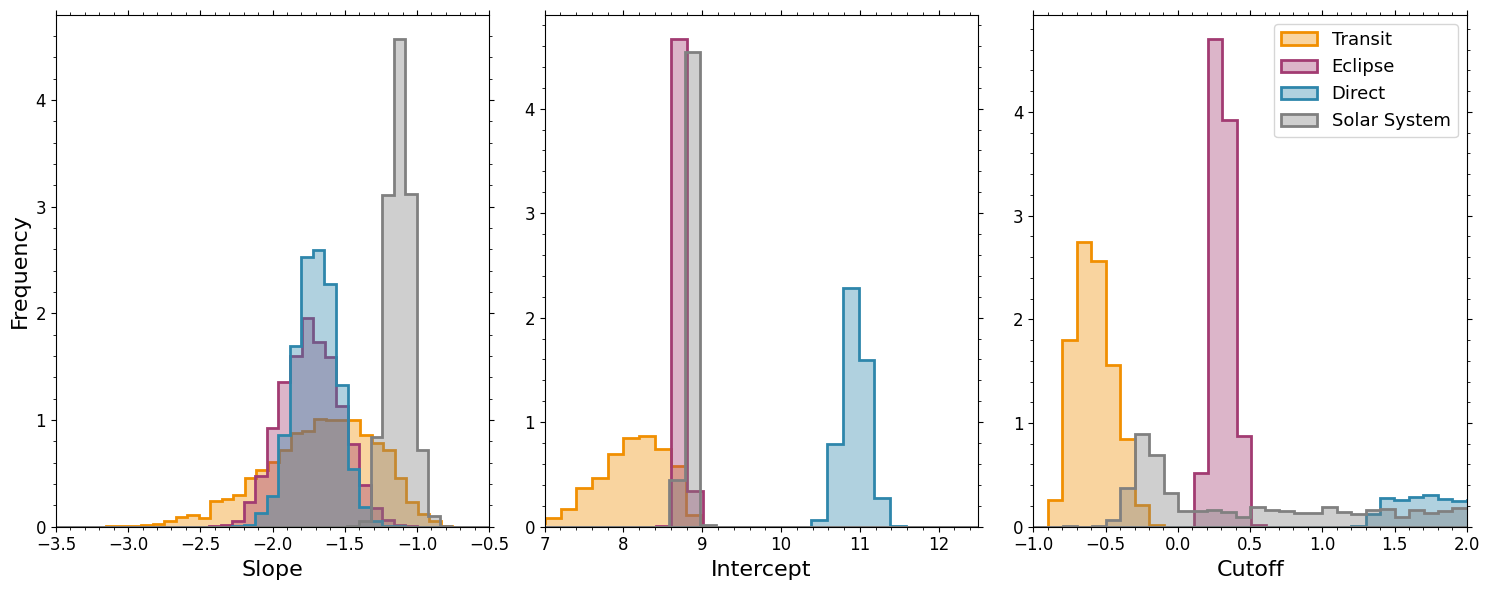
[51]:
import numpy as np
import matplotlib.pyplot as plt
from dynesty import NestedSampler
from dynesty.plotting import runplot, traceplot, cornerplot
# Calculate weighted posterior statistics
def weighted_quantile(values, weights, quantiles):
"""Calculate weighted quantiles"""
sorted_indices = np.argsort(values)
sorted_values = values[sorted_indices]
sorted_weights = weights[sorted_indices]
cumsum = np.cumsum(sorted_weights)
cumsum /= cumsum[-1] # normalize
return np.interp(quantiles, cumsum, sorted_values)
def mass_mh_dynesty(dataset, plot_it=True, xerrs=True, oh = False, ch = False):
# Generate synthetic data
#np.random.seed(42)
#n_data = 50
#x_true = np.linspace(0, 10, n_data)
#m_true, b_true, sigma_true = 2.5, 1.0, 0.5
# True line with noise
#y_true = m_true * x_true + b_true
#y_obs = y_true + np.random.normal(0, sigma_true, n_data)
y_obs = dataset['Metallicity'].values
ylow = dataset['Metallicity Lower'].values
yhigh = dataset['Metallicity Upper'].values
if oh is True:
y_obs = dataset['O/H'].values
ylow = dataset['O/H Lower'].values
yhigh = dataset['O/H Upper'].values
if ch is True:
y_obs = dataset['C/H'].values
ylow = dataset['C/H Lower'].values
yhigh = dataset['C/H Upper'].values
#y_err_u =
x_true = np.log10(dataset['Mass'].values)
if xerrs is True:
x_err = np.max([np.log10(dataset['Mass'].values+dataset['Mass Upper'].values) - np.log10(dataset['Mass'].values),
np.log10(dataset['Mass'].values) - np.log10(dataset['Mass'].values)-dataset['Mass Lower'].values],
axis=0)
else:
x_err = np.zeros(len(x_true))
# Define the log-likelihood function
def loglike(theta):
"""Log-likelihood function for linear model y = mx + b + noise"""
m, b, s = theta
#sigma = np.exp(log_sigma) # Use log(sigma) to ensure positivity
# Model prediction
y_model = m * x_true + b
y_model[np.where(x_true > s)[0]] = m * s + b
# to incorporate errors in x, just make an effective error that is yerr**2+(dy/dx * x_err)**2 = yerr**2+(m*xerr)**2
chi2 = 0
for i in range(len(y_model)):
# skipping measurements with only upper or lower limits
# until better implemented
if yhigh[i] == 0.0:
continue
elif ylow[i] == 0.0:
continue
else:
xerr_eff = x_err[i]*m #okay if xerr = 0.0
if y_model[i] > y_obs[i]:
chi2 += ((y_model[i] - y_obs[i]) / np.sqrt(yhigh[i]**2+xerr_eff**2)) ** 2
else:
chi2 += ((y_model[i] - y_obs[i]) / np.sqrt(ylow[i]**2+xerr_eff**2)) ** 2
# Gaussian likelihood
#chi2 = np.sum((y_obs - y_model)**2 / sigma**2)
#for calculating absolute likelihood, let's take max err
sigma = np.sum(np.max([ylow,yhigh],axis=0))
logL = -0.5 * (chi2 + len(y_obs) * np.log(2 * np.pi * sigma**2))
return logL
# Define the prior transform function
def ptform(u):
"""Prior transform function (uniform to parameter space)"""
theta = np.array(u) # u is in [0,1]^ndim
# Transform uniform [0,1] to parameter ranges:
# m: slope [-5, 5]
# b: intercept [-5, 5]
# log_sigma: log(noise) [log(0.01), log(2)]
theta[0] = -5 + 8 * u[0] # m
theta[1] = -5 + 20 * u[1] # b
#theta[1] = -5 + 6 * u[1] #keep metallicity at Mj < 10x solar
#theta[2] = np.log(0.01) + (np.log(2) - np.log(0.01)) * u[2] # log_sigma
theta[2] = -5+10*u[2]
return theta
# Set up the nested sampler
ndim = 3 # m, b, log_sigma
sampler = NestedSampler(loglike, ptform, ndim, nlive=500)
# Run the nested sampling
print("Running nested sampling...")
sampler.run_nested(dlogz=0.1, print_progress=True)
# Get results
results = sampler.results
# Print summary statistics
print(f"\nNested Sampling Results:")
print(f"Log Evidence: {results.logz[-1]:.2f} ± {results.logzerr[-1]:.2f}")
print(f"Number of likelihood evaluations: {results.niter}")
# Extract posterior samples
samples = results['samples']
#weights = results['importance_weights']
#weights = np.exp(results['logwt'])
#weights = results['logwt']
weights = results.importance_weights()
# Calculate weighted posterior statistics
def weighted_quantile(values, weights, quantiles):
"""Calculate weighted quantiles"""
sorted_indices = np.argsort(values)
sorted_values = values[sorted_indices]
sorted_weights = weights[sorted_indices]
cumsum = np.cumsum(sorted_weights)
cumsum /= cumsum[-1] # normalize
return np.interp(quantiles, cumsum, sorted_values)
# Get parameter estimates (median and 68% credible intervals)
params = ['slope (m)', 'intercept (b)', 'cutoff (s)']
#true_values = [m_true, b_true, np.log(sigma_true)]
print(f"\nParameter Estimates:")
print(f"{'Parameter':<12} {'Median':<8} {'68% CI'} {'- / +'}")
print("-" * 45)
for i in range(ndim):
median = weighted_quantile(samples[:, i], weights, [0.5])[0]
ci_low, ci_high = weighted_quantile(samples[:, i], weights, [0.16, 0.84])
#true_val = true_values[i]
median_val = median
ci_low_val = ci_low
ci_high_val = ci_high
param_name = params[i]
print(f"{param_name:<12} {median_val:<8.3f} [{ci_low_val:.3f}, {ci_high_val:.3f}] [{median_val-ci_low_val:.3f}, {ci_high_val-median_val:.3f}]")
if plot_it is True:
# Create plots
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# Plot 1: Data and fitted line
ax1 = axes[0, 0]
#ax1.scatter(x_true, y_obs, alpha=1.0, label='Observed data',zorder=999)
#ax1.plot(x_true, y_true, 'r-', label='True line', linewidth=2)
ax1.errorbar(x_true, y_obs, yerr = [ylow,yhigh], zorder=999,fmt='.',color='k',label='Observed Data')
# Plot posterior samples of the line
n_samples = min(100, len(samples))
indices = np.random.choice(len(samples), n_samples, p=weights/np.sum(weights))
xfake = np.linspace(-2,1.5)
for idx in indices[:50]: # Plot subset for clarity
m_sample, b_sample, s_sample = samples[idx, 0], samples[idx, 1], samples[idx, 2]
y_sample = m_sample * xfake + b_sample
y_sample[np.where(xfake > s_sample)[0]] = m_sample * s_sample + b_sample
ax1.plot(xfake, y_sample, 'k-', alpha=0.1)
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.legend()
ax1.set_title('Data and Posterior Fits')
# Plot 2: Trace plot (evolution of live points)
ax2 = axes[0, 1]
ax2.plot(results['logl'])
ax2.set_xlabel('Iteration')
ax2.set_ylabel('Log Likelihood')
ax2.set_title('Nested Sampling Trace')
ax2.set_yscale('symlog')
# Plot 3: Prior vs Posterior for slope
ax3 = axes[1, 0]
ax3.hist(samples[:, 0], weights=weights, bins=100, alpha=0.7,
density=True, label='Posterior')
#ax3.axvline(m_true, color='r', linestyle='--', label='True value')
ax3.axhline(1/10, color='g', linestyle=':', label='Prior', alpha=0.7) # Prior is uniform over [-5,5]
ax3.set_xlabel('Slope (m)')
ax3.set_ylabel('Density')
ax3.legend()
ax3.set_title('Slope: Prior vs Posterior')
# Plot 4: Prior vs Posterior for intercept
ax4 = axes[1, 1]
ax4.hist(samples[:, 1], weights=weights, bins=100, alpha=0.7,
density=True, label='Posterior')
#ax4.axvline(b_true, color='r', linestyle='--', label='True value')
ax4.axhline(1/10, color='g', linestyle=':', label='Prior', alpha=0.7) # Prior is uniform over [-5,5]
ax4.set_xlabel('Intercept (b)')
ax4.set_ylabel('Density')
ax4.legend()
ax4.set_title('Intercept: Prior vs Posterior')
# Plot 4: Prior vs Posterior for intercept
ax5 = axes[1, 2]
ax5.hist(samples[:, 2], weights=weights, bins=100, alpha=0.7,
density=True, label='Posterior')
#ax4.axvline(b_true, color='r', linestyle='--', label='True value')
#ax4.axhline(1/10, color='g', linestyle=':', label='Prior', alpha=0.7) # Prior is uniform over [-5,5]
ax5.set_xlabel('Cutoff (s)')
ax5.set_ylabel('Density')
ax5.legend()
ax5.set_title('Cutoff: Prior vs Posterior')
plt.tight_layout()
plt.show()
# Optional: Create corner plot if you want to see parameter correlations
# Uncomment the following lines:
fig_corner = cornerplot(results)
plt.show()
return results
[52]:
import numpy as np
import matplotlib.pyplot as plt
from dynesty import NestedSampler
from dynesty.plotting import runplot, traceplot, cornerplot
# Calculate weighted posterior statistics
def weighted_quantile(values, weights, quantiles):
"""Calculate weighted quantiles"""
sorted_indices = np.argsort(values)
sorted_values = values[sorted_indices]
sorted_weights = weights[sorted_indices]
cumsum = np.cumsum(sorted_weights)
cumsum /= cumsum[-1] # normalize
return np.interp(quantiles, cumsum, sorted_values)
def mass_mh_dynesty_flat(dataset, plot_it=True, xerrs=True, oh = False, ch = False):
# Generate synthetic data
#np.random.seed(42)
#n_data = 50
#x_true = np.linspace(0, 10, n_data)
#m_true, b_true, sigma_true = 2.5, 1.0, 0.5
# True line with noise
#y_true = m_true * x_true + b_true
#y_obs = y_true + np.random.normal(0, sigma_true, n_data)
y_obs = dataset['Metallicity'].values
ylow = dataset['Metallicity Lower'].values
yhigh = dataset['Metallicity Upper'].values
if oh is True:
y_obs = dataset['O/H'].values
ylow = dataset['O/H Lower'].values
yhigh = dataset['O/H Upper'].values
if ch is True:
y_obs = dataset['C/H'].values
ylow = dataset['C/H Lower'].values
yhigh = dataset['C/H Upper'].values
#y_err_u =
x_true = np.log10(dataset['Mass'].values)
if xerrs is True:
x_err = np.max([np.log10(dataset['Mass'].values+dataset['Mass Upper'].values) - np.log10(dataset['Mass'].values),
np.log10(dataset['Mass'].values) - np.log10(dataset['Mass'].values)-dataset['Mass Lower'].values],
axis=0)
else:
x_err = np.zeros(len(x_true))
# Define the log-likelihood function
def loglike(theta):
"""Log-likelihood function for linear model y = mx + b + noise"""
b = theta
#sigma = np.exp(log_sigma) # Use log(sigma) to ensure positivity
# Model prediction
#y_model = m * x_true + b
#y_model[np.where(x_true > s)[0]] = m * s + b
y_model = b*np.ones(len(x_true))
# to incorporate errors in x, just make an effective error that is yerr**2+(dy/dx * x_err)**2 = yerr**2+(m*xerr)**2
chi2 = 0
for i in range(len(y_model)):
# skipping measurements with only upper or lower limits
# until better implemented
if yhigh[i] == 0.0:
continue
elif ylow[i] == 0.0:
continue
else:
xerr_eff = 0.0 #okay if xerr = 0.0
if y_model[i] > y_obs[i]:
chi2 += ((y_model[i] - y_obs[i]) / np.sqrt(yhigh[i]**2+xerr_eff**2)) ** 2
else:
chi2 += ((y_model[i] - y_obs[i]) / np.sqrt(ylow[i]**2+xerr_eff**2)) ** 2
# Gaussian likelihood
#chi2 = np.sum((y_obs - y_model)**2 / sigma**2)
#for calculating absolute likelihood, let's take max err
sigma = np.sum(np.max([ylow,yhigh],axis=0))
logL = -0.5 * (chi2 + len(y_obs) * np.log(2 * np.pi * sigma**2))
return logL
# Define the prior transform function
def ptform(u):
"""Prior transform function (uniform to parameter space)"""
theta = np.array(u) # u is in [0,1]^ndim
# Transform uniform [0,1] to parameter ranges:
# m: slope [-5, 5]
# b: intercept [-5, 5]
# log_sigma: log(noise) [log(0.01), log(2)]
#theta[0] = -5 + 8 * u[0] # m
theta[0] = -5 + 20 * u[0] # b
#theta[1] = -5 + 6 * u[1] #keep metallicity at Mj < 10x solar
#theta[2] = np.log(0.01) + (np.log(2) - np.log(0.01)) * u[2] # log_sigma
#theta[2] = -5+10*u[2]
return theta
# Set up the nested sampler
ndim = 1 # m, b, log_sigma
sampler = NestedSampler(loglike, ptform, ndim, nlive=500)
# Run the nested sampling
print("Running nested sampling...")
sampler.run_nested(dlogz=0.1, print_progress=True)
# Get results
results = sampler.results
# Print summary statistics
print(f"\nNested Sampling Results:")
print(f"Log Evidence: {results.logz[-1]:.2f} ± {results.logzerr[-1]:.2f}")
print(f"Number of likelihood evaluations: {results.niter}")
# Extract posterior samples
samples = results['samples']
#weights = results['importance_weights']
#weights = np.exp(results['logwt'])
#weights = results['logwt']
weights = results.importance_weights()
# Calculate weighted posterior statistics
def weighted_quantile(values, weights, quantiles):
"""Calculate weighted quantiles"""
sorted_indices = np.argsort(values)
sorted_values = values[sorted_indices]
sorted_weights = weights[sorted_indices]
cumsum = np.cumsum(sorted_weights)
cumsum /= cumsum[-1] # normalize
return np.interp(quantiles, cumsum, sorted_values)
# Get parameter estimates (median and 68% credible intervals)
params = ['slope (m)', 'intercept (b)', 'cutoff (s)']
#true_values = [m_true, b_true, np.log(sigma_true)]
print(f"\nParameter Estimates:")
print(f"{'Parameter':<12} {'Median':<8} {'68% CI'} {'- / +'}")
print("-" * 45)
for i in range(ndim):
median = weighted_quantile(samples[:, i], weights, [0.5])[0]
ci_low, ci_high = weighted_quantile(samples[:, i], weights, [0.16, 0.84])
#true_val = true_values[i]
median_val = median
ci_low_val = ci_low
ci_high_val = ci_high
param_name = params[i]
print(f"{param_name:<12} {median_val:<8.3f} [{ci_low_val:.3f}, {ci_high_val:.3f}] [{median_val-ci_low_val:.3f}, {ci_high_val-median_val:.3f}]")
if plot_it is True:
# Create plots
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# Plot 1: Data and fitted line
ax1 = axes[0, 0]
#ax1.scatter(x_true, y_obs, alpha=1.0, label='Observed data',zorder=999)
#ax1.plot(x_true, y_true, 'r-', label='True line', linewidth=2)
ax1.errorbar(x_true, y_obs, yerr = [ylow,yhigh], zorder=999,fmt='.',color='k',label='Observed Data')
# Plot posterior samples of the line
n_samples = min(100, len(samples))
indices = np.random.choice(len(samples), n_samples, p=weights/np.sum(weights))
xfake = np.linspace(-2,1.5)
for idx in indices[:50]: # Plot subset for clarity
m_sample, b_sample, s_sample = samples[idx, 0], samples[idx, 1], samples[idx, 2]
y_sample = m_sample * xfake + b_sample
y_sample[np.where(xfake > s_sample)[0]] = m_sample * s_sample + b_sample
ax1.plot(xfake, y_sample, 'k-', alpha=0.1)
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax1.legend()
ax1.set_title('Data and Posterior Fits')
# Plot 2: Trace plot (evolution of live points)
ax2 = axes[0, 1]
ax2.plot(results['logl'])
ax2.set_xlabel('Iteration')
ax2.set_ylabel('Log Likelihood')
ax2.set_title('Nested Sampling Trace')
ax2.set_yscale('symlog')
# Plot 3: Prior vs Posterior for slope
ax3 = axes[1, 0]
ax3.hist(samples[:, 0], weights=weights, bins=100, alpha=0.7,
density=True, label='Posterior')
#ax3.axvline(m_true, color='r', linestyle='--', label='True value')
ax3.axhline(1/10, color='g', linestyle=':', label='Prior', alpha=0.7) # Prior is uniform over [-5,5]
ax3.set_xlabel('Slope (m)')
ax3.set_ylabel('Density')
ax3.legend()
ax3.set_title('Slope: Prior vs Posterior')
# Plot 4: Prior vs Posterior for intercept
ax4 = axes[1, 1]
ax4.hist(samples[:, 1], weights=weights, bins=100, alpha=0.7,
density=True, label='Posterior')
#ax4.axvline(b_true, color='r', linestyle='--', label='True value')
ax4.axhline(1/10, color='g', linestyle=':', label='Prior', alpha=0.7) # Prior is uniform over [-5,5]
ax4.set_xlabel('Intercept (b)')
ax4.set_ylabel('Density')
ax4.legend()
ax4.set_title('Intercept: Prior vs Posterior')
# Plot 4: Prior vs Posterior for intercept
ax5 = axes[1, 2]
ax5.hist(samples[:, 2], weights=weights, bins=100, alpha=0.7,
density=True, label='Posterior')
#ax4.axvline(b_true, color='r', linestyle='--', label='True value')
#ax4.axhline(1/10, color='g', linestyle=':', label='Prior', alpha=0.7) # Prior is uniform over [-5,5]
ax5.set_xlabel('Cutoff (s)')
ax5.set_ylabel('Density')
ax5.legend()
ax5.set_title('Cutoff: Prior vs Posterior')
plt.tight_layout()
plt.show()
# Optional: Create corner plot if you want to see parameter correlations
# Uncomment the following lines:
fig_corner = cornerplot(results)
plt.show()
return results
[ ]: